CUDA 2.4 组织并行线程
从前面的博客中,我们知道了CUDA变成的几个基本知识,包括内存、kernel等知识点,这里我们就来看看如何组织线程,如果使用了合适的网络和块大小来正确地组织线程,确定每一个线程都是怎么确定唯一的索引,然后建立并行计算,并且不同的线程组织形式是怎么影响性能的。
对于举证运算,传统的方法是在内核中使用一个包含二维网络与二维块的布局来组织线程。但是,这种传统的方法是无法获得最佳性能,在矩阵加法中使用以下的布局会有助于了解更多关于网格和块的启发性和用法:
由二维线程块构成的二维网格
由一维线程块构成的一维网格
由一维线程块构成的二维网格
2.4.1 使用块和线程建立矩阵索引
多线程的优点就是每个线程处理不同的数据计算,那怎么分配好每个线程来处理不同的数据?多线程只能在有效组织合理干活的情况下才能获得更好的性能。
下图是一个很形象的线程模型,不过注意硬件实际的执行和存储不是按照图中的模型来的,需要结合实际情况来理解。
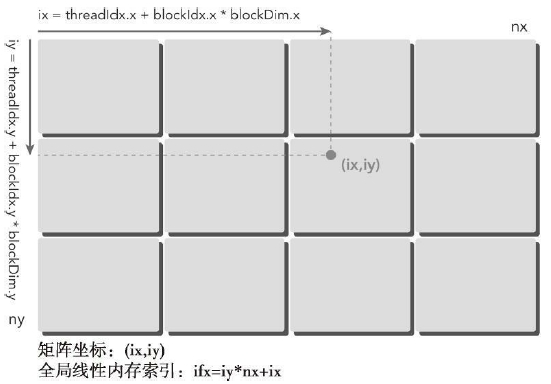
这里$(ix,iy)$就是整个线程模型中任意一个线程的索引,或者叫做全局地址。局部地址就是$(threadIdx.x,threadIdx.y)$了。不过这个局部地址只能找线程块内的线程,不同线程块中会有相同的局部索引值。就比如在同一个小区,A栋有8楼,B栋也有8楼,A栋和B栋就是blockIdx,而8就是threadIdx。
图中的横坐标就是:
$$ix = blockIdx.x * blockDim.x + threadIdx.x$$
纵轴坐标就是:
$$iy = blockIdx.y * blockDim.y + threadIdx.y$$
这样就可以得到每个线程的唯一标号,并且在运行时,kernel是可以获取到这个标号的。
如果每个不同的线程执行同样的代码,又处理同一组数据,将会得到多个相同的结果,这样就没有意义了。为了让不同线程处理不同的数据,CUDA常用的做法是让不同的线程对应不同的数据(用线程的全局标号对应不同的数据)
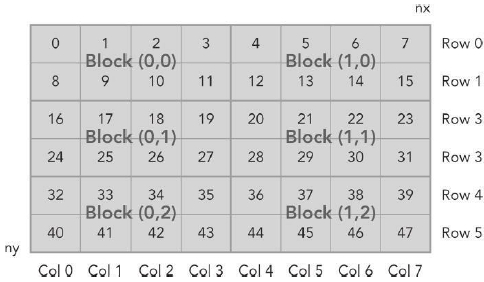
设备内存或者主机内存都是线性的方式存储的,比如一个二维矩阵 (8×6)
,存储在内存中是这样的:

我们需要管理的是:
线程和块索引(来计算线程的全局索引)
矩阵中给定点的坐标$(ix,iy)$
全局线性内存中的偏移量【$(ix,iy)$对应的线性内存的位置】
其线性位置的计算方法是:
$$idx=ix+iy∗nx$$
通过上面的方式我们就可以计算出了线程的全局坐标,用线程的全局坐标对应矩阵的坐标。也就是说,线程的坐标(ix,iy)对应矩阵中(ix,iy)的元素,这样就形成了一一对应,不同的线程处理矩阵中不同的数据
举个具体的例子,ix=10,iy=10的线程去处理矩阵中(10,10)的数据,当然你也可以设计别的对应模式,但是这种方法是最简单出错可能最低的。
我们接下来的代码来输出每个线程的标号信息。首先我们准备线程的部分函数,以此实现:
输出线程在二维网格中的标号,块的标号
计算全局索引
对应数组A对应的值:
__global__ void printThreadIndex(int *A, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d,%d) global index"
" %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y,
ix, iy, idx, A[idx]);
}
主函数的部分:
int main(int argc, char **argv)
{
// 设置矩阵维数
int nx = 8;
int ny = 6;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
// malloc 主机内存
int *h_A;
h_A = (int *)malloc(nBytes);
// 用整数(int)初始化矩阵
for (int i = 0; i < nxy; i++)
{
h_A[i] = i;
}
printMatrix(h_A, nx, ny);
// malloc gpu 设备内存
int *d_MatA;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
// 将数据从主机传输到设备
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
// set up execution configuration
dim3 block(4, 2);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// 调用内核
printThreadIndex<<<grid, block>>>(d_MatA, nx, ny);
CHECK(cudaGetLastError());
// 释放内存
CHECK(cudaFree(d_MatA));
free(h_A);
// 重置设备
CHECK(cudaDeviceReset());
return (0);
}输出结果:
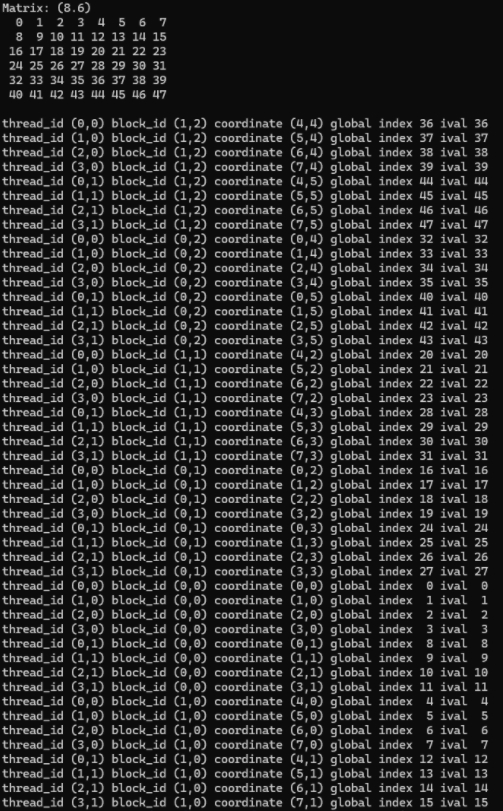
该部分完整代码放在附录 1 里,下图说明了这三项索引之间的关系。
2.4.2 不同的矩阵加法
现在我们可以知道每一个线程已经对应到了不同的数据,接着我们就要用这个方法来进行计算了。
我们可以使用最简单二维矩阵加法来实验。
首先编写一个检验主函数来验证矩阵加法的正确性:
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++){
for (int ix = 0; ix < nx; ix++){
ic[ix] = ia[ix] + ib[ix];}
ia += nx;
ib += nx;
ic += nx;
}
return;
}每个维度下的矩阵大小可以按如下方法设置为16384个元素:
int nx = 1 << 14;
int ny = 1 << 14;1、二维网格和二维块对矩阵求和
我们创建一个核函数,用来做二维线程块来进行矩阵求和:
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}这个核函数的关键步骤是将每个线程从他的线程索引映射到全局线性内存索引中,

int dimx_2d = 32;
int dimy_2d = 32;
dim3 block_2d(dimx_2d, dimy_2d);
dim3 grid_2d((nx + block_2d.x - 1) / block_2d.x, (ny + block_2d.y - 1) / block_2d.y);
iStart = seconds();
sumMatrixOnGPU2D<<<grid_2d, block_2d>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_2d.x,
grid_2d.y,
block_2d.x, block_2d.y, iElaps);运行的效果是:
sumMatrixOnGPU2D <<<(512,512), (32,32)>>> elapsed 0.007960 sec2、一维网格和一维块对矩阵求和
为了使用一维网格和一维块, 我们需要写一个新的核函数, 其中每个线程处理ny个数据元素, 结构如下:
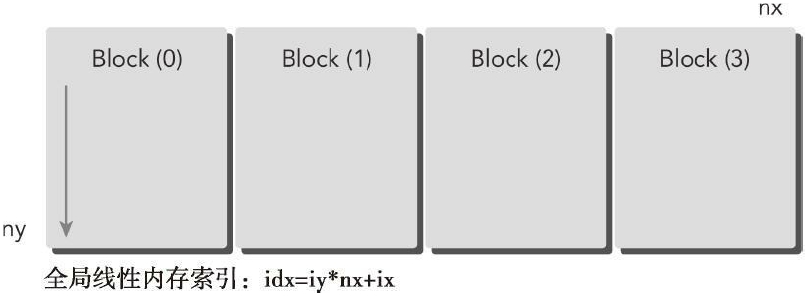
由于在新的核函数中每个线程都要处理ny个元素, 与使用二维网格和二维块的矩阵求和的核函数相比,
从线程和块索引到全局线性内存索引的映射都将会有很大不同。
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx )
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}由于在这个核函数启动中使用了一个一维块布局, 因此只有threadIdx.x是有用的,
并且使用内核中的一个循环来处理每个线程中的ny个元素。
int dimx_1d = 32;
dim3 block_1d(dimx_1d, 1);
dim3 grid_1d((nx + block_1d.x - 1) / block_1d.x, 1);
iStart = seconds();
sumMatrixOnGPU1D<<<grid_1d, block_1d>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_1d.x,
grid_1d.y,
block_1d.x, block_1d.y, iElaps);运行的效果是:
sumMatrixOnGPU1D <<<(512,1), (32,1)>>> elapsed 0.009308 sec3、二维网格和一维块对矩阵求和
当使用一个包含一维块的二维网格时,每个线程都只关注一个数据元素并且网格的第二个维数等于ny
如下图:
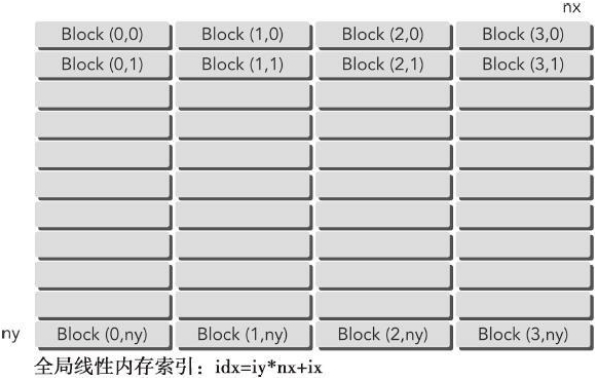
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}这可以看作是含有一个二维块的二维网格的特殊情况, 其中块的第二个维数是1。
因此,从块和线程索引到矩阵坐标的映射就变成:
int dimx_mix = 32;
dim3 block_mix(dimx_mix, 1);
dim3 grid_mix((nx + block_mix.x - 1) / block_mix.x, ny);
iStart = seconds();
sumMatrixOnGPUMix<<<grid_mix, block_mix>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_mix.x,
grid_mix.y,
block_mix.x, block_mix.y, iElaps);运行结果:
sumMatrixOnGPU1D <<<(512,1), (32,1)>>> elapsed 0.009308 sec完整代码在附录中。
附录
0、头文件CHECK函数
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \
fprintf(stderr, "code: %d, reason: %s\n", error, \
cudaGetErrorString(error)); \
exit(1); \
} \
}1、checkThreadIndex.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
void printMatrix(int *C, const int nx, const int ny)
{
int *ic = C;
printf("\nMatrix: (%d.%d)\n", nx, ny);
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
printf("%3d", ic[ix]);
}
ic += nx;
printf("\n");
}
printf("\n");
return;
}
__global__ void printThreadIndex(int *A, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d,%d) global index"
" %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y,
ix, iy, idx, A[idx]);
}
int main(int argc, char **argv)
{
// set matrix dimension
int nx = 8;
int ny = 6;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
// malloc host memory
int *h_A;
h_A = (int *)malloc(nBytes);
// iniitialize host matrix with integer
for (int i = 0; i < nxy; i++)
{
h_A[i] = i;
}
printMatrix(h_A, nx, ny);
// malloc device memory
int *d_MatA;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
// set up execution configuration
dim3 block(4, 2);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// invoke the kernel
printThreadIndex<<<grid, block>>>(d_MatA, nx, ny);
CHECK(cudaGetLastError());
// free host and devide memory
CHECK(cudaFree(d_MatA));
free(h_A);
// reset device
CHECK(cudaDeviceReset());
return (0);
}2、sumMatrixOnGPU-SUM.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n");
else
printf("Arrays do not match.\n");
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
// grid 1D block 1D
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx )
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC2d, *d_MatC1d, *d_MatCMix;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC2d, nBytes));
CHECK(cudaMalloc((void **)&d_MatC1d, nBytes));
CHECK(cudaMalloc((void **)&d_MatCMix, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx_2d = 32;
int dimy_2d = 32;
dim3 block_2d(dimx_2d, dimy_2d);
dim3 grid_2d((nx + block_2d.x - 1) / block_2d.x, (ny + block_2d.y - 1) / block_2d.y);
int dimx_mix = 32;
dim3 block_mix(dimx_mix, 1);
dim3 grid_mix((nx + block_mix.x - 1) / block_mix.x, ny);
int dimx_1d = 32;
dim3 block_1d(dimx_1d, 1);
dim3 grid_1d((nx + block_1d.x - 1) / block_1d.x, 1);
iStart = seconds();
sumMatrixOnGPU2D<<<grid_2d, block_2d>>>(d_MatA, d_MatB, d_MatC2d, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_2d.x,
grid_2d.y,
block_2d.x, block_2d.y, iElaps);
iStart = seconds();
sumMatrixOnGPUMix<<<grid_mix, block_mix>>>(d_MatA, d_MatB, d_MatC1d, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_mix.x,
grid_mix.y,
block_mix.x, block_mix.y, iElaps);
iStart = seconds();
sumMatrixOnGPU1D<<<grid_1d, block_1d>>>(d_MatA, d_MatB, d_MatCMix, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid_1d.x,
grid_1d.y,
block_1d.x, block_1d.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side and check results
CHECK(cudaMemcpy(gpuRef, d_MatC1d, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nxy);
CHECK(cudaMemcpy(gpuRef, d_MatC2d, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nxy);
CHECK(cudaMemcpy(gpuRef, d_MatCMix, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC1d));
CHECK(cudaFree(d_MatC2d));
CHECK(cudaFree(d_MatCMix));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}


