CUDA 2.3 给核函数计时
在内核的性能转换过程中,了解核函数的执行需要多长时间是很有帮助并且十分关键的。
衡量核函数性能的方法有很多。最简单的方法是在主机端使用一个CPU或GPU计时器来计算内核的执行时间。
本节我们从计时器入手,了解如何在CPU或GPU获取代码的运行时长,并了解性能调优的基本概念
一、用CPU计时器计时
C语言中,平时大家最常用的是time.h的头文件来计时:
clock_t start,end;
start = clock();
//要被计算的函数
end = clock();
duration = (double)(end - start) / CLOCKS_PER_SEC;其中,clock函数测出来的时间为进程运行时间,单位为滴答数(ticks)
我们还可以使用gettimeofday系统调用来创建一个CPU计时器获取系统的时钟时间,它将返回从1970年1月1日零点开始到现在的秒数。
因为gettimeofday是linux下的一个库函数,程序中需要添加sys/time.h头文件
#include <sys/time.h>
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp,NULL);
return((double)tp.tv_sec+(double)tp.tv_usec*1e-6);
}然后这个函数就可以用来计时了。我们可以用来给核函数计时,看看他运行了多长时间:
double iStart,iElaps;
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;变量iElaps表示程序运行的时间,就像用手表记录的核函数的执行时间(用秒计算)。
由于核函数调用与主机端程序是异步的,就需要用cudaDeviceSynchronize函数来等待所有的GPU线程运行结束。
-
如果不加这个同步函数,那么计时的时间是从调用核函数,到核函数返回给主机线程的时间段,而不是核函数的执行时间
-
用
cudaDeviceSynchronize函数后,计时是从调用核函数开始,到核函数执行完并返回给主机的时间段
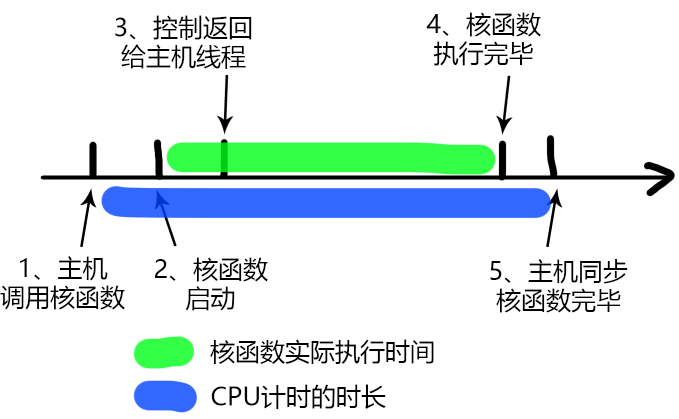
我们可以从上图大概分析下核函数启动到结束的过程:
- 主机线程启动核函数
- 核函数启动成功
- 控制返回主机线程
- 核函数执行完毕
- 主机同步函数侦测到核函数执行完成
我们要测试的是2~4的时间,但是用CPU计时方法,只能测试1~5的时间,所以测试得到的时间偏长。
二、代码实现
现在,通过设置数据集大小来对一个有16M个元素的大向量进行测试,直接用左移比特位来设置:
int nElem = 1 << 24;我们编写核函数的时候,由于GPU的可扩展性,使得我们需要借助块和线程的索引来计算一个按行优先的数组索引 i,并对核函数进行修改。
需要添加限定条件**(i<N)**来检验索引值是否越界
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}为了解决创建的线程总数大于向量元素总数的情况,我们还需要限制内核不能非法访问全局内存,也就是向量元素总数<线程总数
我们除了上面这个核函数我们需要调整以外,只需要写主函数了,这里只介绍主函数编写。
同时我们把这个排错用的函数定义放在头文件里了,加载头文件后直接CHECK()调用即可:
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \
fprintf(stderr, "code: %d, reason: %s\n", error, \
cudaGetErrorString(error)); \
exit(1); \
} \
}初始化数据
- 设置GPU设备
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));- 设置向量的大小
int nElem = 1 << 24;2.1 CPU端的执行方式
- 申请内存空间
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);- 初始化CPU端的数据
double iStart, iElaps;
iStart = seconds();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = seconds() - iStart;
printf("initialData Time elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);- 计算CPU端运行相加花费的时间。
iStart = seconds();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = seconds() - iStart;
printf("sumArraysOnHost Time elapsed %f sec\n", iElaps);2.2 GPU端的执行方式
- 申请内存
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));- 赋值传数据
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));-
定义网络和块
这里的配置设置为一个包含32768个块的一维网格,每个块包含512个线程。
可以自行调整这里的iLen值,试试看1024个线程和512个线程之间性能会提升多少(1.19倍)
int iLen = 512;
dim3 block (iLen);
dim3 grid ((nElem + block.x - 1) / block.x);- 计算GPU运行函数所花费的时间:
iStart = seconds();
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumArraysOnGPU<<<%d, %d>>> Time elapsed %f sec\n",
grid.x,block.x, iElaps);
- 收尾工作,拷贝计算结果并释放内存空间
CHECK(cudaGetLastError()) ;
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nElem);
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);这里在调整执行配置时需要了解的一个关键点是对网格和块维度的限制。线程层次结构中每个层级的最大尺寸取决于设备。
总代码放在文末
三、用nvprof工具计时
自CUDA 5.0以来,NVIDIA提供了一个名为nvprof的命令行分析工具,可以帮助从应用程序的CPU和GPU活动情况中获取时间线信息,其包括内核执行、内存传输以及CUDA API的调用。其用法如下。
nvprof [nvporp_args] <application> [application_args]可以用这个命令测试内核:
nvprof ./test不过吧,计算能力为8.0及以上的设备不支持nvprof。使用
sudo apt install nvidia-nsight下载nsight工具。如果下载出现NO_PUBKEY错误,用下列语句解决:sudo gpg --keyserver keyserver.ubuntu.com --recv-keys 467B942D3A79BD29
使用工具nvprof的计算结果更为精确,因为CPU计时器测量的时间中包含了来自nvprof附加的时间。 工具不仅给出了kernel执行的时间,比例,还有其他cuda函数的执行时间。由nvprof得到的计数器可以帮助我们获取应用程序的指令和内存吞吐量。
主机和设备之间的数据传输需要的时间比内核执行的时间要多。对于HPC工作负载,理解程序中通信比的计算是非常重要的。
如果应用程序用于计算的时间大于数据传输所用的时间,那么或许可以压缩这些操作,并完全隐藏与传输数据有关的延迟。如果应用程序用于计算的时间少于数据传输所用的时间,那么需要尽量减少主机和设备之间的传输。
四、理论界限最大化
在进行程序优化时,如何将应用程序和理论界限进行比较是很重要的。
如果将应用程序的测量值与理论峰值进行比较,可以判定你的应用程序的性能是受限于算法还是受限于内存带宽的。
我们得到了实际操作值之后,就需要知道能优化的极限值是多少,也就是机器的理论计算极限。这个极限我们永远也达不到,但是我们必须明确的是,比如理论极限是2秒,我们已经从10秒优化到2.01秒了,基本就没有必要再继续优化速度了,而应该考虑买更多的机器或者更新的设备。
我们以Tesla K10为例,可以得到理论上的比率:
-
Tesla K10单精度峰值浮点运算次数
745 MHz核心频率*2 GPU/芯片*(8个多处理器*192个浮点单元*32核心/多处理器)*2
OPS/周期=4.58 TFLOPS(FLOPS表示每秒浮点运算次数)
-
Tesla K10内存带宽峰值2 GPU/芯片*256位*2500 MHz内存时钟*2 DDR/8位/字节=320 GB/s
-
指令比∶字节
4.58 TFLOPS/320 GB/s,也就是13.6个指令:1个字节
对于Tesla K10而言,如果你的应用程序每访问一个字节所产生的指令数多于13.6,那么应用程序受算法性能限制。大多数HPC工作负载受内存带宽的限制。
完整代码:
#include "../common.h" //CHECK所在头文件
#include <cuda_runtime.h>
#include <stdio.h>
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
//检测到误差过大,就指出错误对应的维度
//并把flag置为false
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// 为随机数生成不同的种子
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
//主机用for循环计算结果
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
//cuda核函数计算向量相加
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
int nElem = 1 << 24;
printf("Vector size %d\n", nElem);
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
double iStart, iElaps;
iStart = seconds();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = seconds() - iStart;
printf("initialData Time elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
iStart = seconds();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = seconds() - iStart;
printf("sumArraysOnHost Time elapsed %f sec\n", iElaps);
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
int iLen = 512;
dim3 block (iLen);
dim3 grid ((nElem + block.x - 1) / block.x);
iStart = seconds();
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumArraysOnGPU<<<%d, %d>>> Time elapsed %f sec\n",
grid.x,block.x, iElaps);
CHECK(cudaGetLastError()) ;
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nElem);
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}


