CUDA 2.2:线程与核函数
本篇承接上一篇文章:CUDA 2.1 CUDA模型与内存分配
一、线程管理
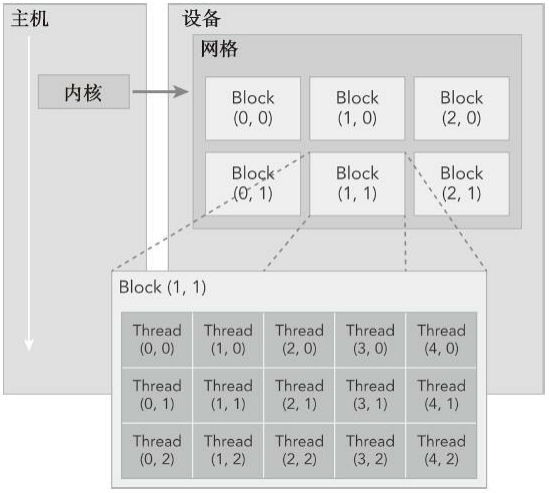
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程 ,并且每个线程都执行由核函数指定的语句。CUDA明确了线程层次抽象的概念,以便于我们组织线程。
这是一个两层的线程层次结构,由线程块和线程块网格构成。
-
由一个内核启动所产生的所有线程统称为一个网格。
同一网格中的所有线程共享相同的全局内存空间。
-
一个网格由多个线程块构成
一个线程块包含一组线程。
同一线程块block内的线程协作可以通过以下方式来实现。
- 同步
- 共享内存
不同块内线程不能相互影响,他们是物理隔离的!
我们必须明确,一个核函数只能有一个网络(grid),一个网络可以有很多个块(block),每个块可以有很多的线程。
线程依靠以下两个坐标变量来区分彼此。这里的Idx是index的缩写
-
blockIdx(线程块在线程格内的索引)
-
threadIdx(块内的线程索引)
这些变量是核函数中需要预初始化的内置变量。当执行一个核函数时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx。基于坐标,可以将部分数据分配给不同的线程。
该坐标变量基于uint3定义的、CUDA内置的向量类型。是一个包含3个无符号整数的结构,可以通过x、y、z三个字段来指定。
blockIdx.x
blockIdx.y
blockIdx.z
threadIdx.x
threadIdx.y
threadIdx.z网格和块的维度一般是二维和三维的,也就是说一个网格通常被分成二维的块,而每个块常被分成三维的线程。
CUDA可以组织三维的网格和块。如上图,是一个包含二维块的二维网格。
网格和块的维度由下列两个内置变量指定:
-
blockDim(线程块的维度,用每个线程块中的线程数来表示)
-
gridDim(线程格的维度,用每个线程格中的线程数来表示)
它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度。当定义一个dim3类型的变量时,所有未指定的元素都被初始化为1。dim3类型变量中的每个组件可以通过它的x、y、z字段获得。
blockDim.x
blockDim.y
blockDim.zdim3是手工定义的,主机端可见。uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了。他们是有区别的!这一点必须要注意。
1、网格和线程块的维度
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。
线程格和线程块均使用3个dim3类型的无符号整型字段,而未使用的字段将被初始化为1且忽略不计。
我们可以通过以下demo进一步了解块的索引和维度。
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void checkIndex(void)
{
//每个线程都会输出自己的索引和维度
printf("threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim:(%d,%d,%d)\
gridDim(%d,%d,%d)\n",
threadIdx.x,threadIdx.y,threadIdx.z,
blockIdx.x,blockIdx.y,blockIdx.z,blockDim.x,blockDim.y,blockDim.z,
gridDim.x,gridDim.y,gridDim.z);
}
int main(int argc,char **argv)
{
//定义一个较小的数据
int nElem=6;
//定义尺寸
dim3 block(3);
//网格大小是块大小的倍数,后续会解释
dim3 grid((nElem+block.x-1)/block.x);
printf("grid.x %d grid.y %d grid.z %d\n",grid.x,grid.y,grid.z);
printf("block.x %d block.y %d block.z %d\n",block.x,block.y,block.z);
checkIndex<<<grid,block>>>();
cudaDeviceReset();
return 0;
}编译输出后:
grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
threadIdx:(0,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(1,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(2,0,0) blockIdx:(0,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(0,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(1,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)
threadIdx:(2,0,0) blockIdx:(1,0,0) blockDim:(3,1,1) gridDim(2,1,1)可以看到,每个线程都有自己的坐标,所有的线程都有相同的块维度和网格维度。
2、主机端和设备端访问(网格/块)变量
区分主机端和设备端的网格和块变量的访问是很重要的
对于一个给定的数据大小,确定网格和块尺寸的一般步骤为:
-
确定块的大小
-
在已知数据大小和块大小的基础上计算网格维度要确定块尺寸,通常需要考虑:
-
内核的性能特性
-
GPU资源的限制
以下demo介绍如何在主机上定义网格和块的大小
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc, char **argv)
{
int nElem = 1024;
dim3 block (1024);
dim3 grid ((nElem + block.x - 1) / block.x);
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 512;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 256;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 128;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
cudaDeviceReset();
return(0);
}由于应用程序中的数据大小是固定的,因此当块的大小发生改变时,相应的网格尺寸也会发生改变。
CUDA的特点之一就是通过编程模型揭示了一个两层的线程层次结构。由于一个内核启动的网格和块的维数会影响性能,所以我们在优化程序的时候要考虑到这一途径。
网格和块从逻辑上表示了一个核函数的线程层次结构。在CUDA执行模型部分中,你就会发现这种线程组织方式能够在不同的设备上执行相同的程序代码,且每一个线程组织具有不同数量的计算和内存资源。
二、核函数概念
在C语言中调用函数是使用如下方式:
function_name(argument list);CUDA核函数调用外加了三个尖括号,<<<>>>运算符内是核函数的执行配置。
kernel_name<<<grid,block>>>(argument list)执行配置的第一个值是网格维度,也就是启动块的数目。第二个值是块维度,也就是每个块中线程的数目。
通过指定网格和块的维度,你可以进行以下配置:
-
内核中线程的数目
-
内核中使用的线程布局
同一个块中的线程之间可以相互协作,不同块内的线程不能协作。
对于一个给定的问题,可以使用不同的网格和块布局来组织你的线程。
例如,假设你有32个数据元素用于计算,每8个元素一个块,需要启动4个块:
kernel_name<<<4,8>>>(argument list)在这里,我们可以使用int类型的变量,或者常量直接初始化。
上述代码的线程布局如下:

核函数是同时复制到多个线程执行的,为了让多线程按照我们的意愿对应到不同的数据,就要给线程一个唯一的标识。
由于数据在全局内存中是线性存储的,我们可以用变量blockIdx.x和threadId.x来进行以下操作
-
在网格中标识一个唯一的线程
-
建立线程和数据元素之间的映射关系
补充:如果把所有32个元素放到一个块里,那么只会得到一个块:
kernel_name<<<1,32>>>(argument list)如果每个块只含有一个元素,那么会有32个块:
kernel_name<<<32,1>>>(argument list)上述代码如果没有特殊结构在核函数中,执行结果应该一致,但是有些效率会一直比较低。
上面这些是启动部分,核函数的调用与主机线程是异步的。核函数调用结束后,控制权立刻返回给主机端。 也就是说,当主机启动了核函数,控制权马上回到主机,而不是主机等待设备完成核函数的运行
想要主机等待设备端执行可以用下面这个函数,来强制主机端程序等待所有的核函数执行结束:
cudaError_t cudaDeviceSynchronize(void);这是一个显示的方法,对应的也就有隐式方法。
隐式方法就是不明确说明主机要等待设备端,而是设备端不执行完,主机没办法进行,比如内存拷贝函数:
cudaError_t cudaMemcpy(void* dst,const void * src,
size_t count,cudaMemcpyKind kind);这个函数在上文有介绍过,当核函数启动后的下一条指令就是从设备复制数据回主机端,那么主机端必须要等待设备端计算完成。
这里再做一次强调:不同于C语言的函数调用,所有的CUDA核函数的启动都是异步的。CUDA内核调用完成后,控制权立刻返回给CPU。
三、编写核函数
我们会启动核函数了,接下来就是自己定义属于自己的核函数了。
核函数也是一个函数,但是声明核函数有一个比较模板化的方法:
__global__ void kernel_name(argument list);注意:声明和定义是不同的,这点CUDA与C语言是一致的
在C语言函数前没有的限定符__global__ ,CUDA C中还有一些其他我们在C中没有的限定符,如下:
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从计算能力3以上的设备调用 | 必须有一个void的返回类型 |
| device | 设备端执行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 | 可以省略 |
其中,__device__和__host__限定符可以一起使用,这样函数可以同时在主机和设备端进行编译。
CUDA Kernel核函数有以下几个限制,适用于所有核函数:
-
只能访问设备内存
-
必须具有void返回类型
-
不支持可变数量的参数
-
不支持静态变量
-
显示异步行为
介绍完规则,我们来看一下并行程序经常出现的一种优化现象:把串行代码并行化时对串行代码块for的操作,也就是把for并行化。
例如在串行条件下,我们会这么写循环:
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}在并行情况,我们可以这么写:
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}你可能已经注意到循环体已经消失了,内置的线程坐标变量替换了数组索引,由于N是被隐式定义用来启动N个线程的,所以N就没有什么参考价值了。
假设有一个长度为32个元素的向量,你可以按以下方法用32个线程来调用核函数:
sumArraysOnGPU<<<1,32>>>(float *A, float *B, float *C)四、处理错误
由于许多CUDA调用是异步的,所以有时会很难确定某个错误是由哪一步程序引起的。
我们可以定义一个错误处理宏封装所有的CUDA API调用,简化了错误检查过程:
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \
fprintf(stderr, "code: %d, reason: %s\n", error, \
cudaGetErrorString(error)); \
exit(1); \
} \
}例如,可以在以下代码中使用宏:
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));如果内存拷贝或之前的异步操作产生了错误,这个宏会帮我们报告错误代码,并输出一个可读信息。
也可以用下述方法,在核函数调用后检查核函数错误:
kernel_function<<<grid,block>>>(argument list);
CHECK(cudaDeviceSynchronize());CHECK(cudaDeviceSynchronize())会阻塞主机端线程的运行,直到设备端所有的请求任务都结束,并保证最后核函数的启动部分不会出错。
以上仅是以调试为目的的,因为在核函数启动后添加这个检查点会阻塞主机端线程,使该检查点成为全局屏障。
五、完善demo
在上一篇文章中,我们用普通C语言实现一个demo,并尝试换用一部分cuda内存分配的api。
实现目标:两个数组的相加
数组a的第一个元素与数组b的第一个元素相加,得到的结果作为数组c的第一个元素,重复这个过程直到数组中的所有元素都进行了一次运算。
我们在这里把该demo完善一下:
先写最简单的初始化数据:
void initialData(float *ip, int size)
{
// 为随机数生成不同的种子
time_t t;
srand((unsigned) time(&t));
//给每个维度都设置随机数
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}主函数
#include "../common/common.h" //CHECK所在头文件
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// 设置设备
int dev = 0;
CHECK(cudaSetDevice(dev));
// 设置向量的数据大小
int nElem = 1 << 5;
printf("Vector size %d\n", nElem);
// malloc主机内存
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// 在主机端初始化数据
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// malloc设备全局内存
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// 将数据从主机传输到设备
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// 在主机端调用内核
dim3 block (nElem);
dim3 grid (1);
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
printf("Execution configure <<<%d, %d>>>\n", grid.x, block.x);
// 将内核结果复制回主机端
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// 在主机端添加向量用来进行结果检查
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// 检查设备结果
checkResult(hostRef, gpuRef, nElem);
// 释放设备全局内存
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// 释放主机内存
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
CHECK(cudaDeviceReset());
return(0);
}定义主机计算向量的函数,用来当正确答案用:
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
//主机用for循环计算结果
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}编写核函数的向量计算:
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
//cuda核函数计算向量相加
int i = threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}最后封装一下检验答案的函数:
void checkResult(float *hostRef, float *gpuRef, const int N)
{
//定义误差值
double epsilon = 1.0E-8;
//定义flag
bool match = 1;
//hostRef是主机计算的正确答案,
//gpuRef是GPU计算的答案
//int N是输入维度
for (int i = 0; i < N; i++)
{
//检测到误差过大,就指出错误对应的维度
//并把flag置为false
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}本篇CUDA编程模型的概述就到这里结束。下一篇开始会具体介绍CUDA编程模型中的核函数计时,并行线程,设备管理等内容。



