CUDA 2.1:CUDA模型与内存分配
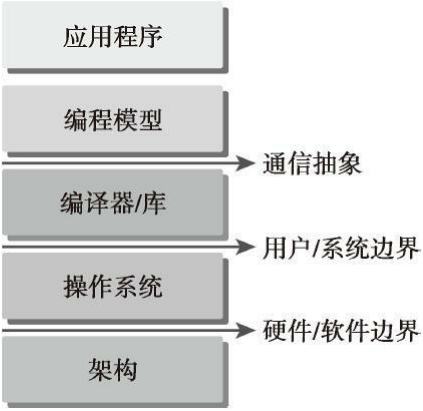
CUDA编程模型为应用和硬件设备之间的桥梁,所以要知道,CUDA C是编译型语言,不是解释型语言。 下面的结构图片能形象的表现程序和编程模型实现之间的抽象结构的重要。
通信抽象,是编程模型和编译器,库函数之间的分界线。
我们要用到的语法,内存结构,线程结构等这些我们写程序时我们自己控制的部分,控制了异构计算设备的工作模式,都是属于编程模型。
它通过专业的硬件原语和操作系统的编译器或库来实现。
利用编程模型所编写的程序指定了程序的各组成部分是如何共享信息及相互协作的。编程模型从逻辑上提供了一个特定的计算机架构,通常它体现在编程语言或编程环境中。
GPU中大致可以分为:
核函数
内存管理
线程管理
流
等几个关键部分。
以上这些理论同时也适用于其他非CPU+GPU异构的组合。
GPU架构下有几个特有的功能:
通过组织层次结构在GPU上组织线程的方法
通过组织层次结构在GPU上组织内存的方法
从宏观上我们可以从以下几个环节完成CUDA应用开发:
- 领域层
- 逻辑层
- 硬件层
-
在第一步、编程与算法设计的过程中,我们最关心的是在领域层如何解析数据和函数,以便在并行环境中正确、高效地解决问题。
-
编程阶段中,我们的关注点应转向如何组织并发线程。 这个阶段要从逻辑层面思考。
在C语言并行编程中,需要使用pthreads或OpenMP技术来显式地管理线程。CUDA提出了一个线程层次结构抽象的概念,以允许控制线程行为。
这个抽象为并行变成提供了良好的可扩展性(一个CUDA程序可以在不同的GPU机器上运行,即使计算能力不同)。
所以说,理解在硬件层上,线程是如何映射到机器上就很重要了。这能帮助我们提高性能。
1、CUDA编程结构
一个异构环境,通常有多个CPU&多个GPU。他们都通过PCIe总线相互通信,也是通过PCIe总线分隔开的。所以我们要区分一下两种设备的内存:
- 主机(Host):CPU及其内存
- 设备(Device):GPU及其内存
这两个内存从硬件到软件都是隔离的(CUDA6.0 以后支持统一寻址,可使用单个指针访问CPU和GPU内存)
我们暂时先把统一寻址放一边,先用内存来回拷贝的方法来编写调试程序,以巩固对两个内存隔离这个事实的理解。
内核(kernel)是CUDA编程模型的一个重要组成部分,其代码在GPU上运行。
多数情况下,主机可以独立地对设备进行操作。内核一旦被启动,管理权立刻返回给主机,释放CPU来执行由设备上运行的并行代码实现的额外的任务。
CUDA编程模型主要是异步的,因此在GPU上进行的运算可以与主机-设备通信重叠。一个典型的CUDA程序包括由并行代码互补的串行代码。
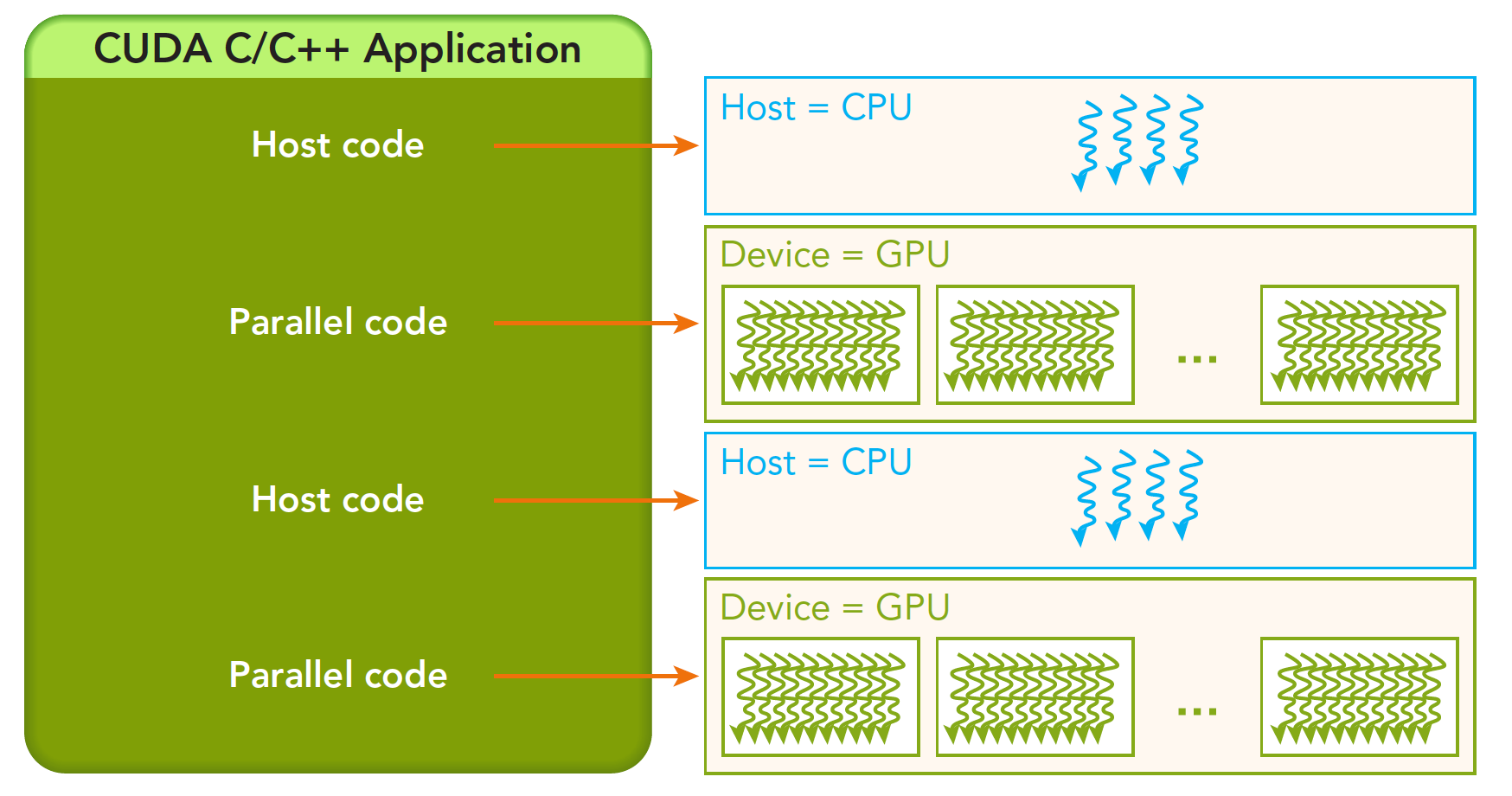
如下图,串行代码(及任务并行代码)在主机CPU上执行,而并行代码在GPU上执行。主机代码按照ANSI C标准进行编写,而设备代码使用CUDA C进行编写。
一个典型的CUDA程序实现流程遵循以下模式,参考下图:
1.把数据从CPU内存拷贝到GPU内存。
2.调用核函数对存储在GPU内存中的数据进行操作。
3.将数据从GPU内存传送回到CPU内存。
2、内存管理
内存管理在传统串行程序是很常见的。寄存器空间,栈空间内的内存由机器自己管理,堆空间由用户控制分配和释放。
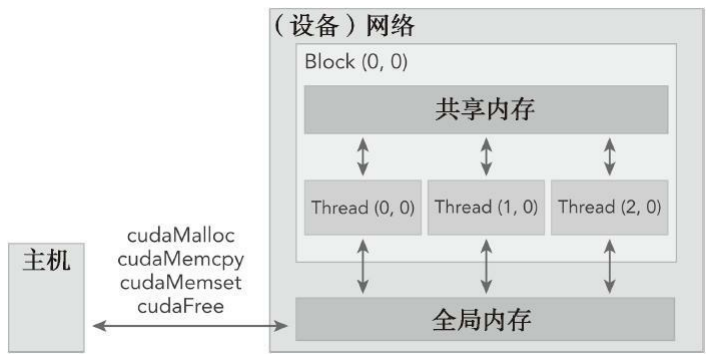
CUDA程序同样,只是CUDA提供的API可以分配管理设备上的内存,也可以用CUDA管理主机上的内存。
用于GPU内存分配的是cudaMalloc函数,其函数原型为:
cudaError_t cudaMalloc (void** devPtr, size_t size)该函数负责向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
cudaMalloc与标准C语言中的malloc函数基本是一样的,只是这个函数在GPU的内存里分配内存。
通过充分保持与标准C语言运行库中的接口一致性,可以实现CUDA应用程序的轻松接入。
下面表格有一些主机API和CUDA C的API的对比:
| 标准C函数 | CUDA C 函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
我们来研究这个表格里最关键的一步,这一步要走总线的。
cudaError_t cudaMemcpy(void * dst,const void * src,size_t count, cudaMemcpyKind kind)这个函数是内存拷贝过程,可以完成以下几种过程(cudaMemcpyKind kind)
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这四个过程的方向可以清楚的从字面上看出来了
这个函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前,主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cudaError_t。
如果GPU内存分配执行成功,则会返回 cudaSuccess ;否则返回 cudaErrorMemoryAllocation
可以使用以下CUDA运行时函数将错误代码转化为可读的错误消息:
char* cudaGetErrorString(cudaError_t error)3、内存层次结构
CUDA编程模型最显著的一个特点就是揭示了内存层次结构。每一个GPU设备都有用于不同用途的存储类型。
在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。
- 全局内存类似于CPU的系统内存
- 共享内存类似于CPU的缓存。
然而GPU的共享内存可以由CUDA C的内核直接控制。
我们通过一个两个数组相加的例子来学习如何在主机和设备之间进行数据传输,以及如何用CUDA C编程。
4、代码
看了这么久的理论,看一下代码放松一下吧🐶
实现目标:两个数组的相加
数组a的第一个元素与数组b的第一个元素相加,得到的结果作为数组c的第一个元素,重复这个过程直到数组中的所有元素都进行了一次运算。
1、编写主函数。
我们先把各个变量初始化一下:
#include <stdlib.h>
#include <time.h>
int main(int argc, char **argv)
{
// 初始化数组大小
int nElem = 1024;
size_t nBytes = nElem * sizeof(float);
// 分配三个同样大小的空间
float *h_A, *h_B, *h_C;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
h_C = (float *)malloc(nBytes);
// 生成随机数
initialData(h_A, nElem);
initialData(h_B, nElem);
// 相加
sumArraysOnHost(h_A, h_B, h_C, nElem);
// 释放空间
free(h_A);
free(h_B);
free(h_C);
return(0);
}其中随机数的函数定义如下:
void initialData(float *ip, int size)
{
//随机种子
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}最后是相加函数:
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
{
C[idx] = A[idx] + B[idx];
}
}我们可以用gcc之类的C语言编译,也可以使用前一篇介绍的nvcc编译方式编译:
nvcc -Xcompiler -std=c99 sum.c -o sum
./sum-Xcompiler用于指定命令行选项是指向C编译器还是预处理器。
这里的例子中,将-std=c99传递给编译器,因为这里的C程序是按照C99标准编写的。
可以在这个网站找到编译器选项:cuda c
改成CUDA代码!
现在,聪明的你可以在GPU上修改代码来进行数组加法运算,用我们刚刚了解到的cudaMalloc在GPU上申请内存。
float *d_A, *d_B, *d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);然后,可以使用cudaMemcpy函数把数据从主机内存拷贝到GPU的全局内存中,参数cudaMemcpyHostToDevice指定了数据拷贝方向。
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);当数据被转移到GPU的全局内存后,主机端调用核函数在GPU上进行数组求和。
一旦内核被调用,控制权立刻被传回主机,这样的话,当核函数在GPU上运行时,主机可以执行其他函数。因此,内核与主机是异步的。
当内核在GPU上完成了对所有数组元素的处理后,其结果将以数组d_C的形式存储在GPU的全局内存中,然后用cudaMemcpy函数把结果从GPU复制回到主机的数组gpuRef中。
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost)cudaMemcpy的调用会导致主机运行阻塞。cudaMemcpyDeviceToHost的作用就是将存储在GPU上的数组d_c中的结果复制到gpuRef中。最后,调用cudaFree释放GPU的内存。
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);在这补充一点:CUDA C编程一个经常会发生的错误就是:混用设备和主机的内存地址
如果你执行了错误的内存分配,如:
gpuRef = d_C而不是正确的方式:
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost)应用程序就会崩溃
为了区分设备和主机端内存,我们可以给变量加后缀或者前缀
h_表示host,d_表示device并且为了避免这类错误,CUDA 6.0提出了统一寻址,使用一个指针来访问CPU和GPU的内
存。(当然是以后再介绍了)
很明显,现在我们只是入门了基本的内存处理,要想完善这个demo,我们还需要学习很多。下一篇我们会接着介绍CUDA线程管理



