CUDA 1:并行基础概念
我们传统的计算机结构一般是哈佛体系结构(后来演变出冯·诺依曼结构)
主要分成三部分:
- 内存(指令内存,数据内存)
- 中央处理单元(控制单元和算数逻辑单元)
- 输入、输出接口
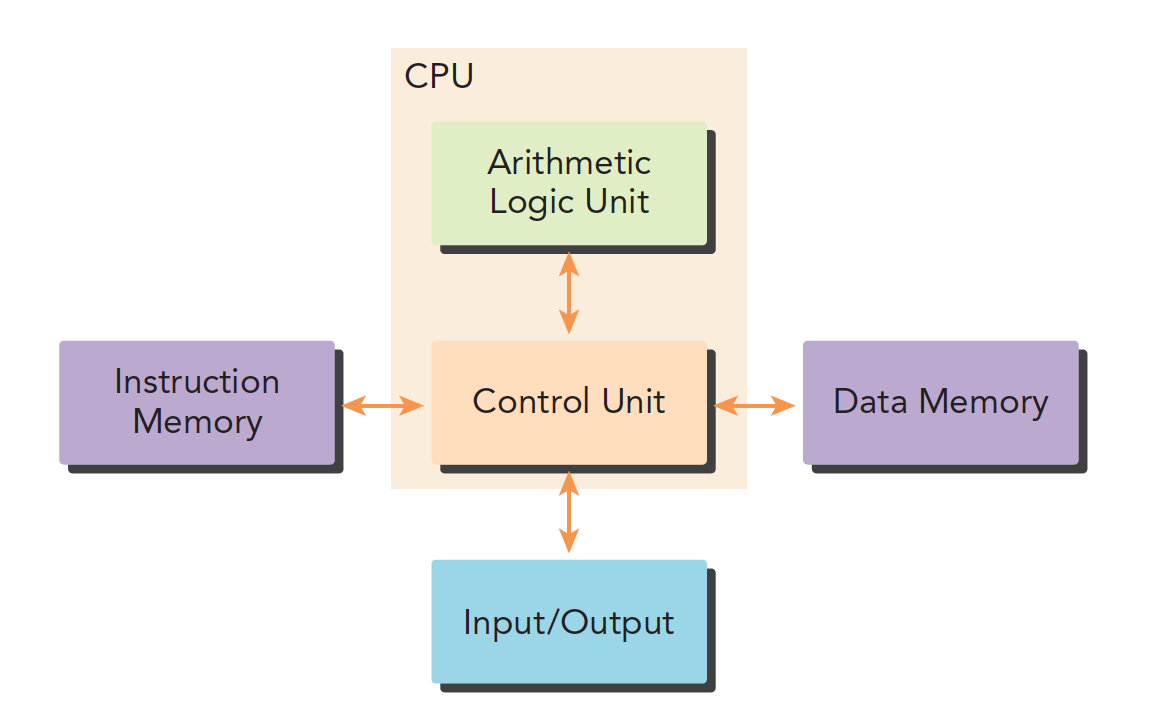
写并行程序的时候,需要对硬件有一定的了解。
一、并行性
写并行程序可以分解任务。我们一般把一个程序看成是指令和数据的组合。
并行分为以下两种:
-
任务并行
许多任务或函数可以独立地、大规模地并行执行。任务并行的重点在于利用多核系统对任务进行分配
-
数据并行
同事处理多个数据。数据并行的重点在于利用多核系统对数据进行分配
而CUDA就很适合解决数据并行计算的问题
数据并行设计,第一步就是把数据,依据线程进行划分。
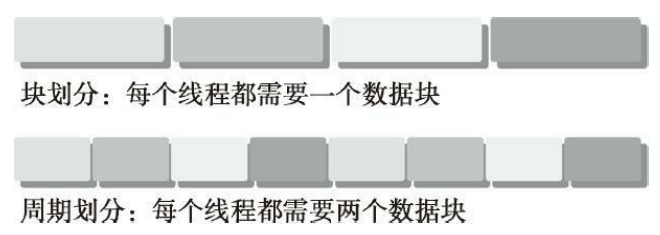
数据并行有两种方案,块划分和周期划分:
-
块划分(block partitioning)
-
一组连续的数据放在一个块里,把这一整块数据切成小块
-
每个小块随机的划分给一个线程,每个块的执行顺序随机
-
线程通常在同一个时间内只处理一个数据块
thread 1 2 3 4 5 block 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -
-
周期划分(cyclic partitioning)
-
更少的数据被分到在一个块中,相邻的线程处理相邻的数据块。
-
每个线程可以处理多个数据块。
-
比如我们有五个线程,线程1执行块1,线程2执行块2……线程5执行块5,线程1执行块6
thread 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 block 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -
如下图所示:
块划分中,每个线程只需要处理数据的一部分
通常这些数据大小相同
周期划分中,每个线程要处理数据的多个部分
颜色相同的块使用的同一个线程,从执行顺序上看如下:
程序的性能对块的大小比较敏感,不同的数据划分严重影响程序性能。
针对不同的问题和不同计算机结构,我们要通过和理论和试验共同来决定最终最优的数据划分。

二、计算机架构
1、佛林分类法
有多种不同的方法可以对计算机架构进行分类。一个广泛使用的分类方法是弗林分类法(Flynn’s Taxonomy),它根据指令和数据进入CPU的方式,将计算机架构分为4种不同的类型
-
单指令单数据(SISD)
传统串行计算机
-
单指令多数据(SIMD)
并行架构,有多个核心。
比如向量机,所有核心指令唯一,但是数据不同,现在CPU基本都有这类的向量指令
-
多指令单数据(MISD)
比较少见,多个指令群殴一个数据
-
多指令多数据(MIMD)
并行架构,多核心,多指令,异步处理多个数据流,从而实现空间上的并行,MIMD多数情况下包含SIMD,就是MIMD有很多计算核,计算核支持SIMD

为了提高并行的计算能力,我们要从架构上实现以下这些性能的提升:
-
降低延迟
-
其中,延迟是指操作从开始到结束所需要的时间。
一般用微秒计算,延迟越低越好。
-
-
提高带宽
- 带宽是单位时间内处理的数据量,一般用MB/s或者GB/s表示。
-
提高吞吐量
-
吞吐量是单位时间内成功处理的运算数量,一般用gflops来表示(十亿次浮点计算)
吞吐量和延迟有一定关系,都是反映计算速度的,一个是时间除以运算次数,得到的是单位次数用的时间–延迟,一个是运算次数除以时间,得到的是单位时间执行次数–吞吐量。
-
2、根据内存划分
计算机架构也可以根据内存进行划分:
- 分布式内存的多节点系统
- 共享内存的多处理器系统
第一种分布式内存的,通常叫做集群。
可以理解为有好多台电脑,每个电脑都是完整的,有内存处理器电源等一些列硬件。这些电脑通过网络连接互动,这就是分布式。
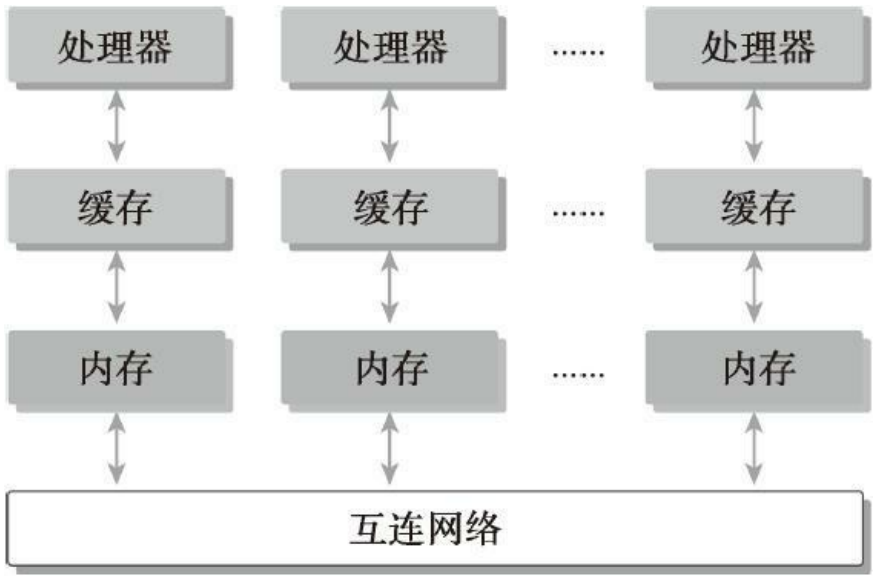
第二种共享内存的,是单个主板有多个处理器,他们共享相同的主板上的内存,内存寻址空间相同,通过PCIe和内存互动。
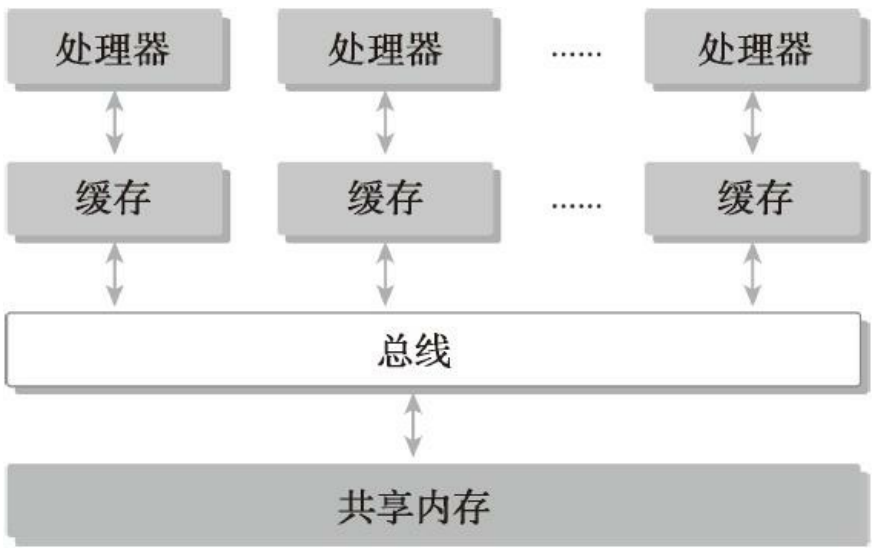
多个处理器可以分多片处理器,和单片多核(众核many-core),也就是有些主板上挂了好多个处理器,也有的是一个主板上就一个处理器,但是这个处理器里面有几百个核。
GPU就属于众核系统。当然现在CPU也都是多核的了,但是他们还是有很大区别的:
- CPU适合执行复杂的逻辑,比如多分支,其核心比较重(复杂),以优化串行程序执行
- GPU适合执行简单的逻辑,大量的数据并行计算,其吞吐量更高,但是核心比较轻(结构简单)
三、异构计算
不同的计算机架构就是异构
x86 CPU+GPU的这种异构应该是最常见的,也有CPU+FPGA,CPU+DSP等各种组合。当然超级计算机大部分也采用异构计算的方式来提高吞吐量。
异构架构虽然比传统的同构架构运算量更大,但是其应用复杂度更高,因为要在两个设备上进行计算,控制,传输,这些都需要人为干预,而同构的架构下,硬件部分自己完成控制,不需要人为设计。
四、异构架构
4.1 CPU与GPU
一个典型的异构计算节点包括两个多核CPU插槽和两个或更多个的众核GPU。
GPU不是一个独立运行的平台,而是CPU的协处理器。因此,GPU必须通过PCIe总线与基于CPU的主机相连来进行操作,
如下图,这就是为什么CPU所在的位置被称作主机端,而GPU所在的位置被称作设备端。
CPU和GPU之间通过PCIe总线连接,用于传递指令和数据,这部分也是后面要讨论的性能瓶颈之一。
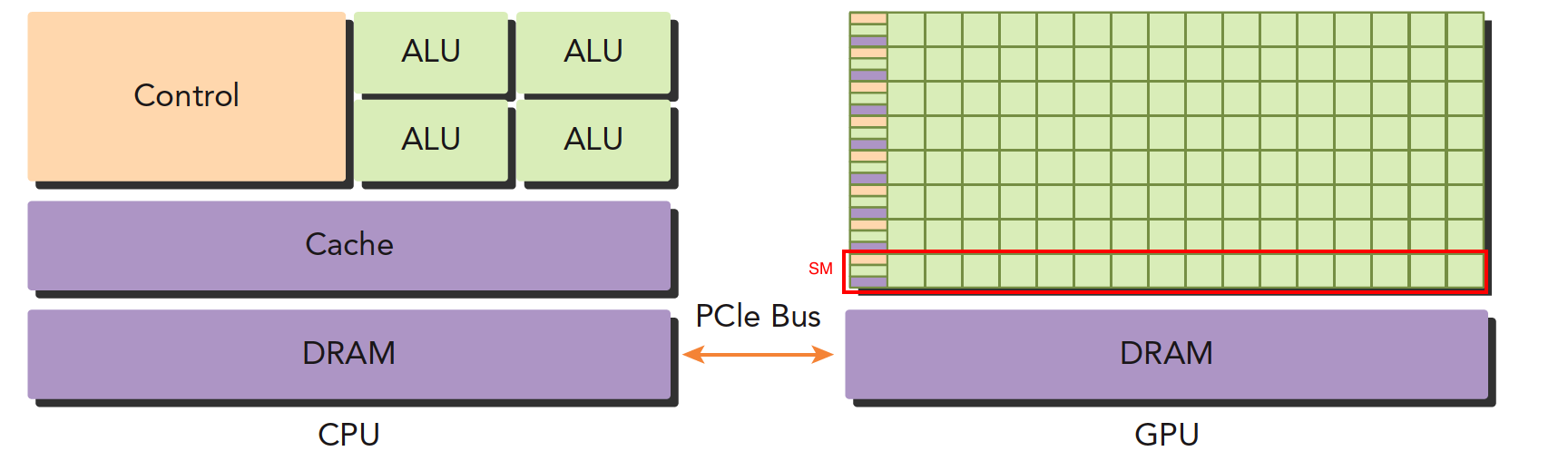
上面这张图能大致反应CPU和GPU的架构不同。
-
左图:一个四核CPU一般有四个ALU(算数逻辑单元,可以做数学运算和逻辑运算)也是我们平时说四核八核的核,控制单元,缓存也在片上,DRAM是内存,CPU一般通过总线访问内存。
-
右图:GPU,绿色小方块是ALU,需要注意以下红色框部分
SM,这一组ALU公用一个Control单元和Cache,这个部分相当于一个完整的多核CPU,但是不同的是ALU多了,control部分变小,可以看到计算能力提升了,相对的控制能力减弱了所以对于控制(逻辑)复杂的程序,一个GPU的SM是没办法和CPU比较的,但是面对逻辑简单,数据量大的任务,GPU更高效。并且一个GPU会有好多个SM。
一个异构应用包括两个部分。
-
主机代码
-
设备代码
主机代码在主机端运行,被编译成主机架构的机器码,设备端的在设备上执行,被编译成设备架构的机器码。
所以主机端的机器码和设备端的机器码是隔离的,自己执行自己的,没办法交换执行。
主机端代码主要是控制设备,完成数据传输等控制类工作,设备端主要的任务就是计算。
因为当没有GPU的时候CPU也能完成这些计算,只是速度会慢很多,所以可以把GPU看成CPU的一个加速设备。
4.2 GPU计算平台
NVIDIA目前的计算平台(不是架构)有:
- Tegra
- Geforce
- Quadro
- Tesla
每个平台针对不同的应用场景,比如:
Tegra用于嵌入式、大规模的并行计算
Geforce面向图形用户,平时打游戏用到
Quadro用于专业绘图设计
Fermi是Tesla系列产品中的一种,用作GPU加速器,近来在高性能计算中获得了广泛应用
以下是描述GPU容量的两个重要特征。
-
CUDA核心数量
-
内存大小
相应的,有两种不同的指标来评估GPU的性能。
-
峰值计算性能
峰值计算性能是用来评估计算容量的一个指标,通常定义为每秒能处理的单精度或双精度浮点运算的数量。峰值性能通常用GFlops(每秒十亿次浮点运算)或TFlops(每秒万亿次浮点运算)来表示。
-
内存带宽
内存带宽是从内存中读取或写入数据的比率。内存带宽通常用 GB/s表示。
nvidia自己有一套描述GPU计算能力的代码,名字是“计算能力”。主要区分不同的架构
| 计算能力 | 架构名 |
|---|---|
| 1.x | Tesla |
| 2.x | Fermi |
| 3.x | Kepler |
| 4.x | Maxwell |
| 5.x | Pascal |
| 6.x | Volta |
这里的Tesla架构,与上面的Tesla平台不同,不要混淆,一个是平台名字,一个是架构名字
五、异构范例
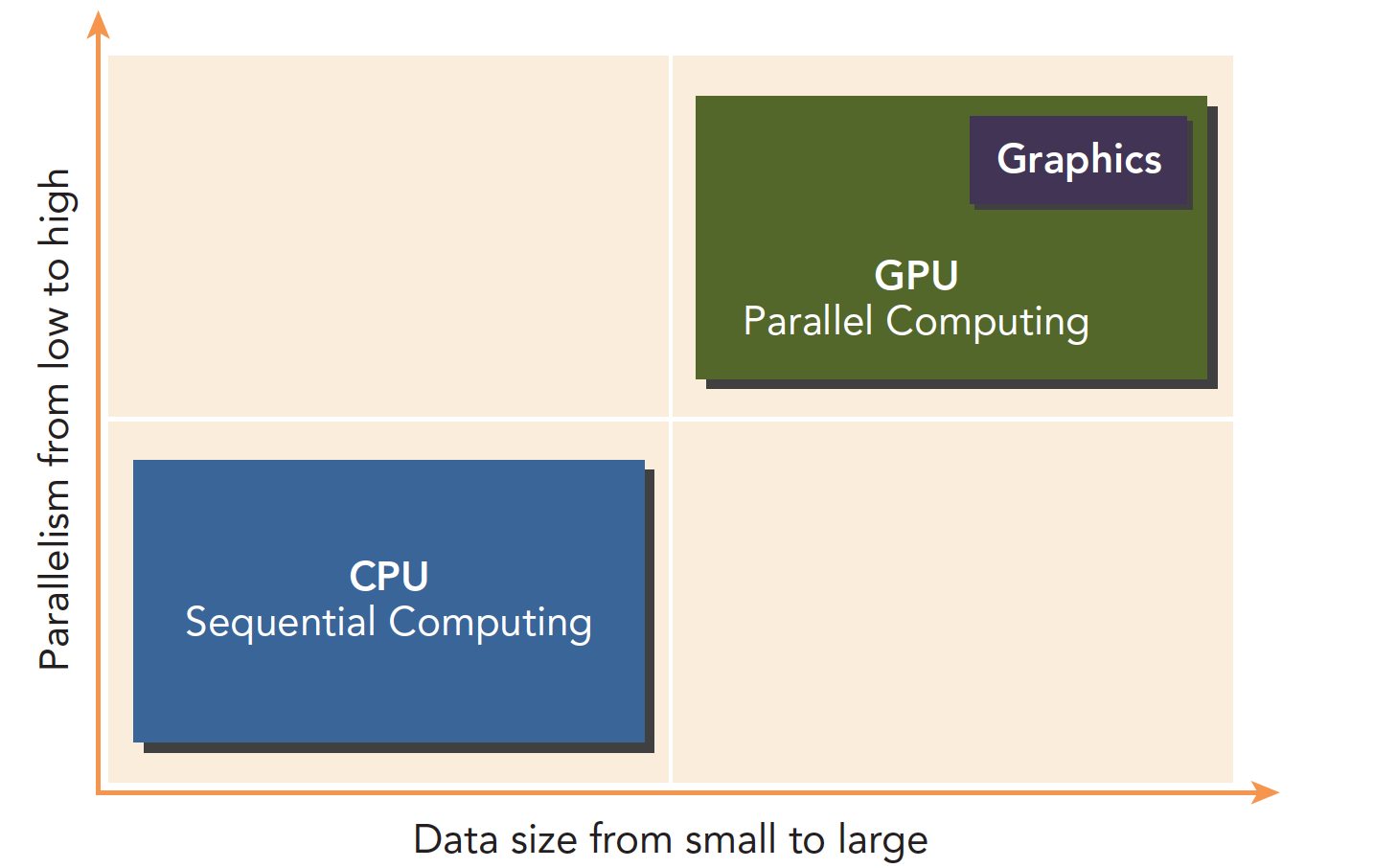
CPU和GPU相互配合,各有所长,各有所短
-
低并行逻辑复杂的程序适合用CPU
-
高并行逻辑简单的大数据计算适合GPU
因为CPU和GPU的功能互补性导致了CPU+GPU的异构并行计算架构的发展,这两种处理器的类型能使应用程序获得最佳的运行效果。
因此,为了获得最佳性能,你可以同时使用CPU和GPU来执行你的应用程序,在CPU上执行串行部分或任务并行部分,在GPU上执行数据密集型并行部分
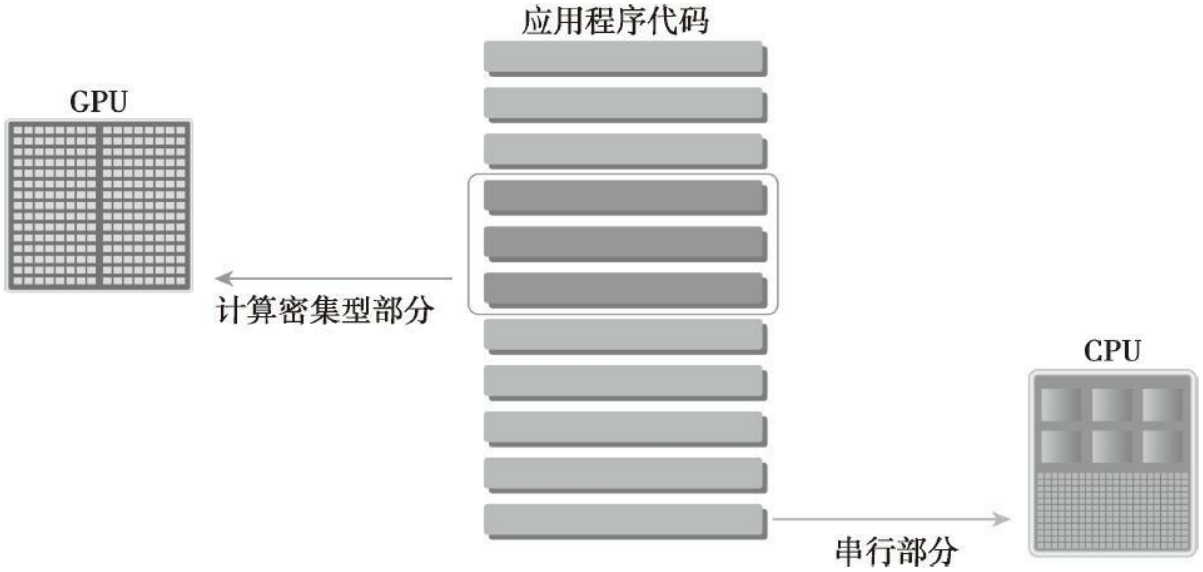
CPU和GPU线程的区别:
- CPU线程是重量级实体,操作系统交替执行线程,线程上下文切换的花销很大
- GPU线程是轻量级的,GPU应用一般包含成千上万的线程,多数在排队状态,线程之间切换基本没有开销。
- CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU核则是大量线程,最大幅度提高吞吐量
这种代码的编写方式能保证GPU与CPU相辅相成,从而使CPU+GPU系统的计算能力得以充分利用。为了支持使用CPU+GPU异构系统架构来执行应用程序,NVIDIA设计了一个被称为CUDA的编程模型
六、CUDA
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持
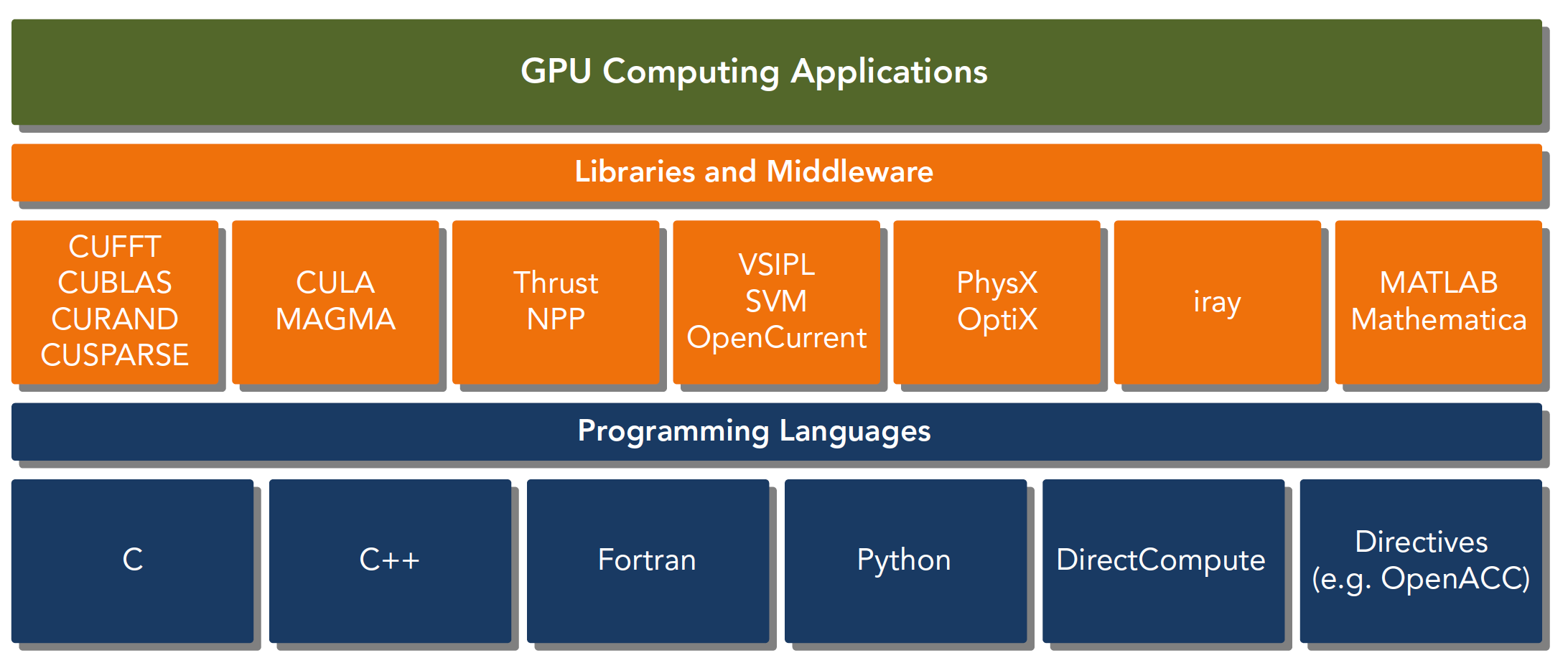
CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端代码,而且CUDA库本身提供了大量API来操作设备完成计算。
对于API也有两种不同的层次,一种相对交高层,一种相对底层。
- CUDA驱动API
- CUDA运行时API
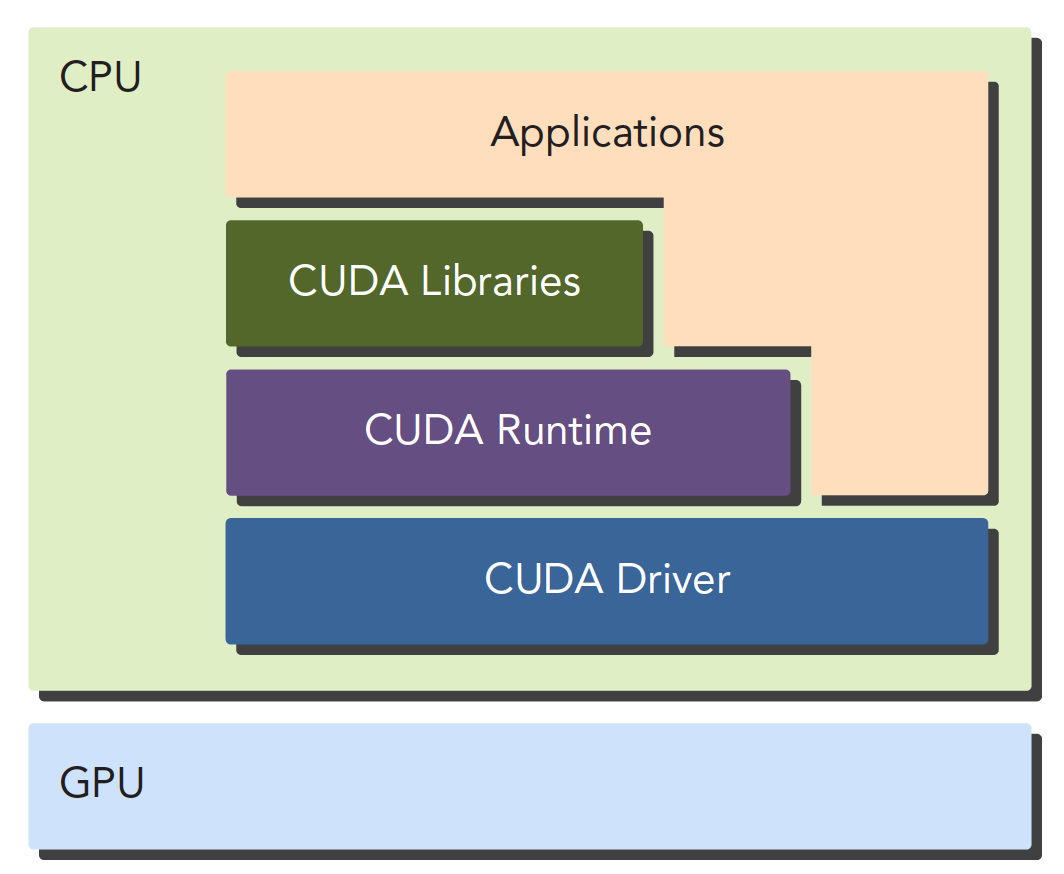
驱动API是低级的API,使用相对困难,运行时API是高级API使用简单,其实现基于驱动API。
这两种API是互斥的,也就是你只能用一个。两者之间的函数不可以混合调用,只能用其中的一个库。
一个CUDA应用通常可以分解为两部分,
- CPU 主机端代码
- GPU 设备端代码
CUDA nvcc编译器会自动分离你代码里面的不同部分
如下图,主机代码用C写成,使用本地的C语言编译器编译。设备端代码,也就是核函数,用CUDA C编写,通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
核函数是设备上执行的程序段
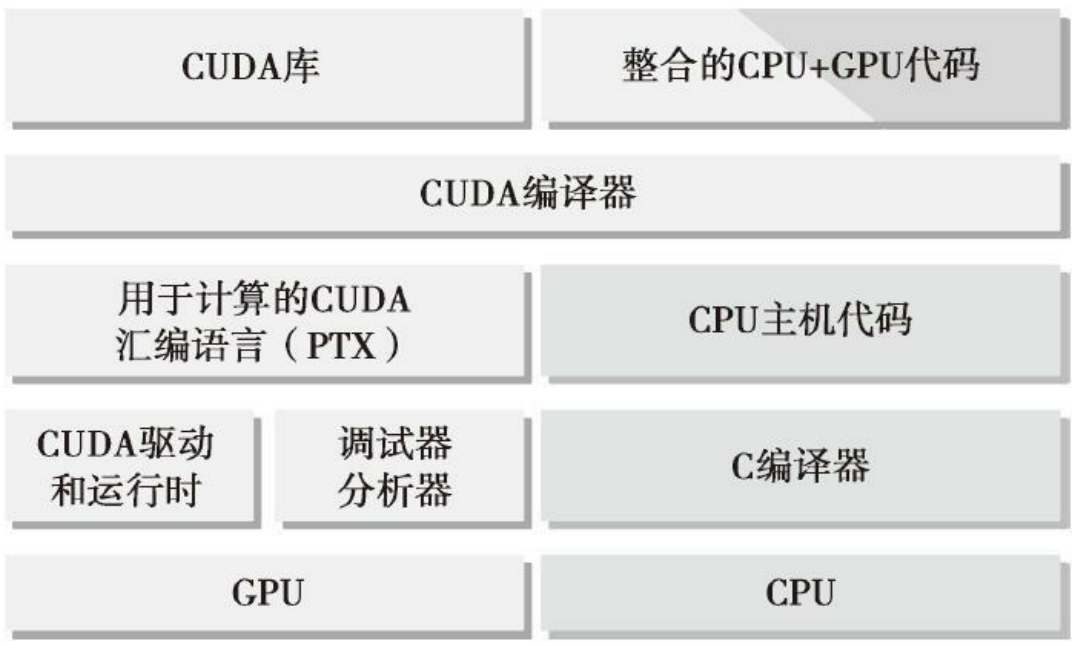
其中,CUDA nvcc编译器是从LLVM开源编译系统为基础开发的。
CUDA为C和C++开发人员提供了一个综合的开发环境。CUDA工具包包括编译器、数学库,以及调试和优化应用程序性能的工具。
七、CUDA “Hello World”
关于CUDA环境配置,本篇不做介绍。不同操作系统需要安装的CUDA和驱动都不一样,本篇使用的是linux系统。具体请参考官网:https://developer.nvidia.com/
以下就是CUDA的Hello World。
#include <stdio.h>
__global__ void helloFromGPU()
{
printf("Hello World from GPU!\n");
}
int main(int argc, char **argv)
{
printf("Hello World from CPU!\n");
helloFromGPU<<<1, 10>>>();
cudaDeviceReset();
return 0;
}其中:
-
__global__的功能是,告诉编译器这个函数将会从CPU中调用,然后在GPU上执行, 是个可以在设备上执行的核函数。 -
<<<>>>是c语言没有的,指从主线程到设备端代码的调用。里面的参数是执行配置,用来说明使用多少线程来执行内核函数。在这个例子中,有10个GPU线程被调用。
-
cudaDeviceRest()用来显式地释放和清空当前进程中与当前设备有关的所有资源。这句话如果没有,则不能正常的运行,因为这句话包含了隐式同步,GPU和CPU执行程序是异步的,核函数调用后成立刻会到主机线程继续,而不管GPU端核函数是否执行完毕,所以上面的程序就是GPU刚开始执行,CPU已经退出程序了,所以我们要等GPU执行完了,再退出主机线程。
编译
可以在LINUX命令行使用以下语句编译:
nvcc hello.cu -o hello这个使用方式和gcc比较接近
前面介绍过,nvidia显卡有不同的架构
使用 NVCC 编译时,可以使用arch 标志 (’ -arch’) 指定了 CUDA 文件将为其编译的 NVIDIA GPU 架构的名称。
以下是 NVIDIA 架构名称的列表,以及它们具有哪些计算能力:
| Fermi | Kepler | Maxwell | Pascal | Volta | Turing | Ampere | Hopper* | Lovelace? |
|---|---|---|---|---|---|---|---|---|
| sm_20 | sm_30 | sm_50 | sm_60 | sm_70 | sm_75 | sm_80 | sm_90 | sm_100? |
| sm_35 | sm_52 | sm_61 | sm_72 | sm_86 | ||||
| sm_37 | sm_53 | sm_62 | sm_87 |
其中:
Fermi 和 Kepler 从 CUDA 9 和 11 起已弃用
Maxwell 从 CUDA 11.6 起已弃用
Hopper 是 NVIDIA 的“tesla-next”系列,采用 5nm 工艺,取代 Ampere。
所以我们也可以使用以下语句编译,指定所需的架构:
nvcc -arch=sm_60 hello.cu -o hello我们还可以使用Makefile来编译:
APPS=hello
all: ${APPS}
%: %.cu
nvcc -O2 -arch=sm_60 -o $@ $<
clean:
rm -f ${APPS}运行
$ ./hello
Hello World from CPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!八、总结
一般CUDA程序分成下面这些步骤:
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核函数来执行计算
- 把计算完成数据拷贝回主机端
- 内存销毁
而上面的Hello World只到第三步,没有进行到内存交换部分。
CPU与GPU的编程主要区别在于对GPU架构的熟悉程度,是否理解机器结构对编程效率影响非常大
一定要了解你的机器,才能写出优秀的代码。且目前计算设备的架构决定了局部性将会严重影响效率。
-
数据局部性分为两种
-
空间局部性:当一个数据被使用,其附近的数据将很快会被使用
-
时间局部性:数据可能会在短时间内被重复使用。
-
-
CUDA中有两个模型是决定性能的:
-
内存层次结构
-
线程层次结构
CUDA C写核函数的时候我们只写一小段串行代码,但是这段代码会被成千上万的线程执行,所有线程执行的代码都是相同的。CUDA编程模型提供了一个层次化的组织线程,会直接影响GPU上的执行顺序。
-
-
CUDA抽象了硬件实现:
- 线程组的层次结构
- 内存的层次结构
- 障碍同步
其中,线程、内存将是CUDA编程主要研究的对象
为此,NVIDIA提供了很多工具:
- Nvidia Nsight集成开发环境
- CUDA-GDB 命令行调试器
- 性能分析可视化工具
- CUDA-MEMCHECK工具
- GPU设备管理工具
后续内容会围绕CUDA展开介绍



