SLAM 4、相机与图像
一、相机模型
1、针孔相机模型
对于成像模型来说,大家是否第一反应是针孔模型?
在一个暗箱的前方放着一支点燃的蜡烛,烛光透过暗箱上的一个小孔投影在暗箱的后方平面上,并在这个平面上形成了一个倒立的蜡烛图像。在这个过程中,小孔模型能够把三维世界中的蜡烛投影到一个二维成像平面。
我们可以用这个模型来简单理解一下相机的成像过程。
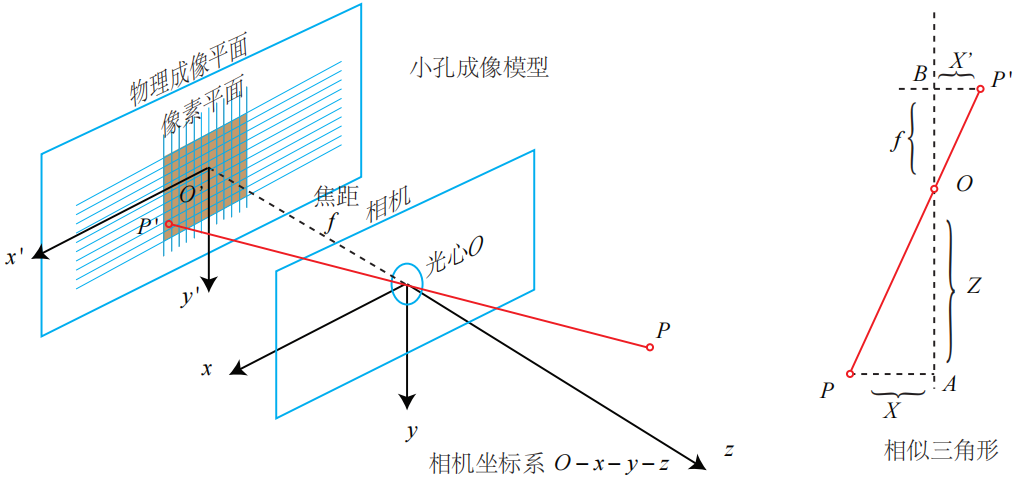
对这个简单的针孔模型进行几何建模可得:设 O−x−y−z为相机坐标系,我们让z轴指向相机前方,x向右,y向下。O为摄像机的光心,也是针孔模型中的针孔。
现实世界的空间点P,经过小孔O投影之后,落在物理成像平面 O′−x′−y′ 上,成像点为P′。设P的坐标为 $[X,Y,Z]^T$,P′ 为 $[X′,Y′,Z′]^T$,并且设物理成像平面到小孔的距离为f(焦距)。根据三角形相似关系,有:
$$
\frac Zf=-\frac{X}{X^{‘}}=-\frac{Y}{Y^{’}}
$$
其中负号表示成的像是倒立的。为了简化模型,我们把成像平面对称到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如下图中间的样子所示。
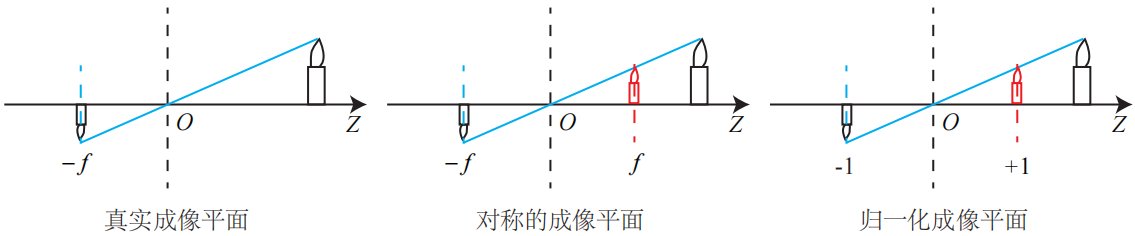
这样做可以把公式中的负号去掉,使式子更简洁:
$$
\frac Zf=\frac{X}{X^{‘}}=\frac{Y}{Y^{’}}
$$
整理得:
$$
X’=f\frac XZ\\
Y’=f\frac YZ
$$
尽管从物理原理来说,小孔成像应该是倒像,但我们对图像作了预处理,所以理解成在对称平面上的像好像并没有什么影响。不引起歧义的情况下,我们就不加限制地称后一种情况为针孔模型。
上式描述了点P与它的像之间的联系。不过,相机最终是获得了一个个像素,这需要对成像平面上进行采样和量化。描述这个像素平面o-u-v,在像素平面即可得到P'的像素坐标$[u,v]^T$。
像素坐标系(图像坐标系)通常定义的方式为:原点o'位于图像的左上角,u轴往右与x轴平行,v轴向下与y轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。
设像素坐标在u轴上缩放了$\alpha$倍,在v轴上缩放了$\beta$倍。同时原点还平移了$[c_x,c_y]^T$。那P'的坐标与像素坐标$[u,v]^T$的关系是:
$$
\left\{\begin{matrix}
u=\alpha X’+c_x \\
v=\beta Y’+c_y
\end{matrix}\right.
$$
代入这个式子:
$$
X’=f\frac XZ\\
Y’=f\frac YZ
$$
并把$\alpha f$合并成$f_x$,把$\beta f$合并成$f_y$,可得:
$$
\left\{\begin{matrix}
u=f\frac XZ+c_x \\
v=f\frac YZ+c_y
\end{matrix}\right.
$$
上式中,f的单位为米,$\alpha,\beta$的单位为像素每米,所以$f_x,f_y$单位为像素。而使用齐次坐标,写成矩阵的形式会更加直观简洁。
$$
\begin{bmatrix}
u\\
v\\
1
\end{bmatrix}=
\frac{1}{Z}
\begin{bmatrix}
f_x & 0 & c_x\\
0 & f_y & c_y\\
0 & 0 & 1
\end{bmatrix}
\begin{bmatrix}
X\\
Y\\
Z
\end{bmatrix}\triangleq
\frac{1}{Z}KP
$$
把Z挪到左边可得:
$$
Z
\begin{bmatrix}
u\\
v\\
1
\end{bmatrix}=
\begin{bmatrix}
f_x & 0 & c_x\\
0 & f_y & c_y\\
0 & 0 & 1
\end{bmatrix}
\begin{bmatrix}
X\\
Y\\
Z
\end{bmatrix}\triangleq
KP
$$
中间的$\begin{bmatrix}f_x & 0 & c_x\\0 & f_y & c_y\\0 & 0 & 1\end{bmatrix}$矩阵称为相机的内参数矩阵(Camera Intrinsics)K,简称内参。确定自己相机内参的过程叫做标定。 现在这个标定也很成熟,如张正友标定法。
与内参对应的是外参:就是相机的位姿。相比不变的内参,外参会随着相机运动而改变,也是SLAM中待估计的目标,他代表着机器人的轨迹。
相机的位姿由旋转矩阵和平移向量来描述,有:
$$
ZP_{uv}=Z
\begin{bmatrix}
u\\
v\\
1
\end{bmatrix}=
K(RP_w+t)=KTP_w
$$
它描述了P的世界坐标到像素坐标的映射关系。这里相机的位姿R,t就是相机的外参。
*补充:这个式子隐含了一次齐次坐标到非齐次坐标的变换,可以看到,右侧的$TP_w$表示把一个世界坐标系下的齐次坐标,变换到相机坐标系下。为了使它与
K相乘,需要取它的前三维组成向量(因为$TP_w$最后一维为1)。此时,对于这个三维向量,我们还可以按照齐次坐标的方式,把最后一维进行归一化处理,得到了P在相机归一化平面上的投影:
$$
\overset{\sim}{P_c}=
\begin{bmatrix}
X\\
Y\\
Z
\end{bmatrix}=
(TP_w)_{(1:3)}\\
P_c=
\begin{bmatrix}
X/Z\\
Y/Z\\
1
\end{bmatrix}
$$这时$P_c$可以看成一个二维的齐次坐标,称为归一化坐标。它位于相机前方$z=1$处的平面上。该平面称为归一化平面。由于$P_c$经过内参之后就得到了像素坐标,所以我们可以把像素坐标$[u,v]^T$,看成对归一化平面上的点进行量化测量的结果。
2、畸变
实际上,相机的前方是有装透镜的
透镜对成像过程中光线的传播会产生一些新的影响:
- 透镜自身的形状对光线传播的影响
- 在机械组装过程中,透镜和成像平面不可能完全平行,这也会影响光线成像时的位置
由透镜形状引起的畸变称之为径向畸变。
我们回顾一下针孔模型中,一条直线投影到像素平面上还是一条直线。
可是,在实际拍摄的照片中,相机是有透镜的。透镜往往使得真实环境中的某一条直线,在图片中变成了曲线。越靠近图像的边缘,这种现象越明显。这是由于实际的透镜往往是中心对称的,这使得不规则的畸变通常径向对称。
径向畸变主要分为两大类:桶形畸变和枕形畸变

桶形畸变是由于图像放大率随着离光轴的距离增加而减小,枕形畸变相反。这两种畸变中,穿过图像中心和光轴有交点的直线还能保持形状不变。
除了透镜的形状导致的径向畸变。在相机的组装过程中,由于不能使得透镜和成像面严格平行,也容易导致切向畸变:
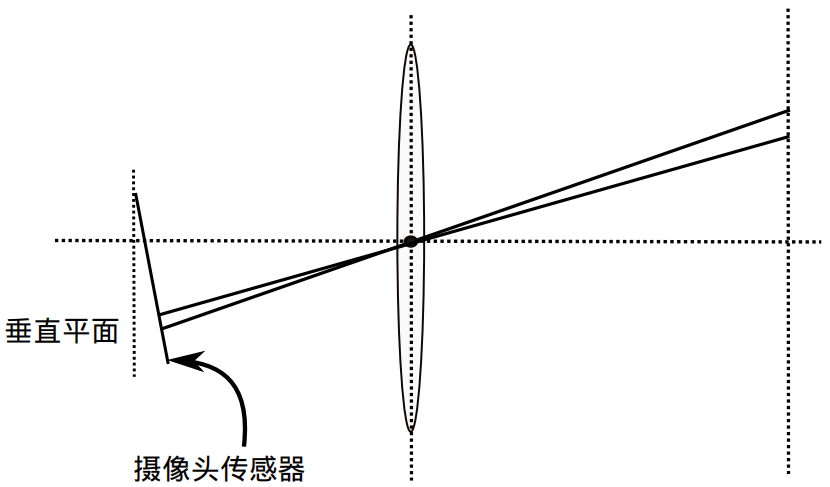
我们用更严格的数学形式对两种畸变进行描述:
知道平面上的任意一点p笛卡尔坐标表示为$[x,y]^T$,也可以把它写成极坐标的形式$[r,\theta]^T$
其中r表示点p离坐标系原点的距离,θ表示和水平轴的夹角。
-
径向畸变:可看成坐标点沿着长度方向发生了变化——其距离原点的长度发生了变化
δr。 -
切向畸变:可看成坐标点沿着切线方向发生了变化——其水平夹角发生了变化
δθ。
1)、径向畸变
对径向畸变来说,无论是桶形畸变还是枕形畸变,它们都是随着离中心的距离增加而增加。所以我们可以用一个多项式函数来描述畸变前后的坐标变化。这类畸变可以用 和距中心距离有关的二次及高次多项式函数 进行纠正:
$$
x_{corrected}=x(1+k_1r^2+k_2r^4+k_3r^6)\\
y_{corrected}=y(1+k_1r^2+k_2r^4+k_3r^6)
$$
其中、$[x,y]^T$是还没纠正的点 的坐标 。$[x_{corrected},y_{corrected}]^T$是纠正好的坐标。
他们都是归一化平面上的点,而不是像素平面的点。
上面式子中,畸变纠正的参数负责的区域不同:
- k1:纠正对于畸变较小的图像中心区域
- k2:纠正对于畸变较大的边缘区域
- k3:纠正畸变超大的摄像头——如鱼眼摄像头
2)、切向畸变
对于切向畸变,使用另外的两个参数p1、p2来进行纠正:
$$
x_{corrected}=x+2p_1xy+p_2(r^2+2x^2)\\
y_{corrected}=y+p_1(r^2+2y^2)+2p_2xy
$$
使用上述这两套式子,使用五个参数就可以完成矫正了。总结一下流程:
-
将三维空间点投影到归一化图像平面。设它的归一化坐标为$[x,y]^T$。
-
对归一化平面上的点进行径向畸变和切向畸变纠正
$$
x_{corrected}=x(1+k_1r^2+k_2r^4+k_3r^6)\\
+x+2p_1xy+p_2(r^2+2x^2)\\
y_{corrected}=y(1+k_1r^2+k_2r^4+k_3r^6)\\
+y+p_1(r^2+2y^2)+2p_2xy\\
$$ -
纠正后的五个点通过内参数矩阵投影到像素平面,得到该点在图像上正确的位置
$$
u=f_xx_{corrected}+c_x\\
v=f_yy_{corrected}+c_y
$$
对于普通相机来说,这样矫正就够了。有时甚至只需要k1、p1、p2就够了
3)、小结
我们小结一下单目相机的成像过程:
-
首先,世界坐标系下有一个固定的点 P,世界坐标为$P_w$;
-
由于相机在运动,它的运动由
R,t或变换矩阵 $T\in SE(3)$描述。P的相机坐标为:$\overset{\sim}{P_c}=RP_w+t$ -
这时的$\overset{\sim}{P_c}$仍有
X,Y,Z三个量,把它们投影到归一化平面Z=1上,得到P的归
一化相机坐标:$P_c=[\frac XZ,\frac YZ,1]^T$。 [1]
- 最后,P 的归一化坐标经过内参后,对应到它的像素坐标:$P_{uv}=Kp_c$。
这里一共有四类坐标系:
-
世界坐标系:人为定义的一种最原始的基础坐标系,用来描述世界中各个物体所处的位置
-
相机坐标系:以相机光心为原点,相机自身的坐标系,是一个三维坐标系
-
图像坐标系:在相机的成像平面上,为了描述相机坐标系的成像情况,所建立的二维坐标系
-
像素坐标系:以成像平面左上角为原点,像素大小为坐标分度值,将图像坐标系上的图像转化为像素坐标信息,是最终获得图片的二维坐标系
3、双目相机模型
仅根据一个像素,是无法确定这个空间点的具体位置的。
因为,从相机光心到归一化平面连线上的所有点,都可以投影至该像素上。只有当P确定时(比如通过双目或 RGB-D 相机),我们才能明确地知道它在三维空间的位置。
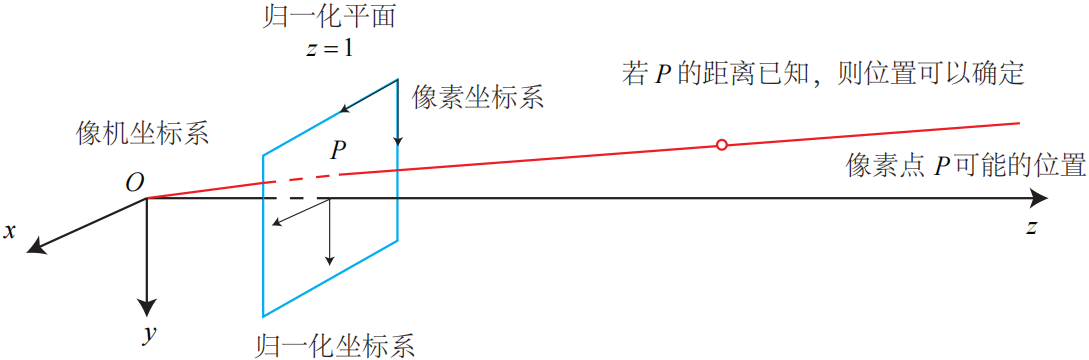
测量像素距离(或深度)的方式有很多种。比如人眼:就可以根据左右眼看到的景物差异(视差)来判断物体与我们的距离。
双目相机的原理就是这样。通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。

上图是双目相机的成像模型。$O_L, O_R$ 为左右光圈中心,蓝色框为成像平面,
f为焦距。$u_L 和 u_R$ 为成像平面的坐标。需要注意的是:按照图中坐标定义,$u_R$ 应该是负数,所以图中标出的距离为$−u_R$。
双目相机一般由左眼和右眼两个水平放置的相机组成。在左右双目的相机中,我们可以把两个相机都看作针孔相机。因为它们是水平放置的,意味两个相机的光圈中心都位于X轴上。它们的距离称为双目相机的基线(Baseline, 记作 b),是双目的重要参数。
现在,考虑一个空间点 P,它在左眼和右眼各成一像,记作$P_L,P_R$。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只有在x轴上有位移,因此P的像也只在x轴(对应图像的u轴)上有差异。我们记它在左侧的坐标为$u_L$,右侧坐标为$u_R$。那么,它们的几何关系如上图右侧所示。根据三角形$P-P_L-P_R$和$P-O_L-O_R$的相似关系,有:
$$
\frac{z−f}{z}=\frac{b−u_L+u_R}{b}
$$
整理一下得:
$$
z=\frac{fb}{u_L-u_R}=\frac{fb}{d}\\
d=u_L-u_R
$$
这里d为左右图的横坐标之差,称为视差(Disparity)。根据视差就可以估计一个像素离相机的距离。
视差与距离成反比——视差越大,距离越近。并且,由于视差最小为一个像素,所以双目的深度存在一个理论上的最大值,由fb确定。所以说,当基线越长时,双目最大能测到的距离就会变远;反之,基线越短,则只能测量很近的距离。
虽然这个公式很简洁,但视差d本身的计算比较困难。我们需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(也就是对应关系),这件事属于“人类觉得容易而计算机觉得困难”的事情。当我们想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。由于计算量的原因,双目深度估计仍需要使用GPU等大算力来计算。这在后面会提及,可以参考本博客CUDA系列文章。
4、RGB-D 相机模型
RGB-D相机模型能够主动测量每个像素的深度。目前的RGB-D相机按原理可分为两大类:
- 通过红外结构光(Structured Light)来测量像素距离的。如 Kinect 1 代、Project Tango 1 代、Intel RealSense 等等

一个RGB-D相机至少会有一个发射器和一个接收器。
无论是结构光还是 ToF,RGB-D 相机都需要向探测目标发射一束光线(通常是红外光)。
-
在结构光原理中,相机根据返回的结构光图案,计算物体离自身的距离。
-
在 ToF 中,相机向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体离自身的距离。
ToF 原理和激光传感器很相似,不过激光是通过逐点扫描来获取距离,而 ToF 相机则可以获得整个图像的像素深度
在测量深度之后,RGB-D 相机能够完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。我们可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。
⚠ BUT,RGB-D 相机有几点劣势:
- 这种类型的发射-接受的测量方式,使得它使用范围比较受限。
- 用红外进行深度值测量的 RGB-D 相机,容易受到日光或其他传感器发射的红外光干扰,因此不能在室外使用;
- 同时使用多个深度相机时也会相互干扰。
- 对于透射材质的物体,因为接受不到反射光,所以无法测量这些点的位置。
- RGB-D 相机本身的成本较大、功耗也比较高。
二、代码
使用eigen、pangolin、opencv编写。环境配置可以网上查、或参照SLAM 2、代码基础.
其中代码的图像资源可以用自己的图,也可以参考slam源码仓库
1、图像去畸变
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
// 需要确定5个畸变参数 k1,k2,k3,p1,p2
// k1,k2,k3 纠正径向畸变
// p1,p2 纠正切向畸变
// 图片文件路径,这里用的灰度图
string image_file = "./distorted.png";
int main(int argc, char **argv) {
// 畸变参数
double k1 = -0.28340811, k2 = 0.07395907, p1 = 0.00019359, p2 = 1.76187114e-05;
// 内参
double fx = 458.654, fy = 457.296, cx = 367.215, cy = 248.375;
// 图像是灰度图,CV_8UC1
cv::Mat image = cv::imread(image_file, 0);
int rows = image.rows, cols = image.cols;
cv::Mat image_undistort = cv::Mat(rows, cols, CV_8UC1); // 去畸变以后的图
// 计算去畸变后图像的内容
for (int v = 0; v < rows; v++) {
for (int u = 0; u < cols; u++) {
// 按照公式,计算点(u,v)对应到畸变图像中的坐标(u_distorted, v_distorted)
double x = (u - cx) / fx, y = (v - cy) / fy;
double r = sqrt(x * x + y * y);
// 归一化平面下的畸变点 x_d
double x_distorted = x * (1 + k1 * r * r + k2 * r * r * r * r) + 2 * p1 * x * y + p2 * (r * r + 2 * x * x);
// 归一化平面下的畸变点 y_d
double y_distorted = y * (1 + k1 * r * r + k2 * r * r * r * r) + p1 * (r * r + 2 * y * y) + 2 * p2 * x * y;
// 再将畸变的归一化下的x_d 和 y_d 变为像素坐标即可
double u_distorted = fx * x_distorted + cx;
double v_distorted = fy * y_distorted + cy;
// 赋值 (使用最近邻插值)
if (u_distorted >= 0 && v_distorted >= 0 && u_distorted < cols && v_distorted < rows) {
image_undistort.at<uchar>(v, u) = image.at<uchar>((int) v_distorted, (int) u_distorted);
}
else {
image_undistort.at<uchar>(v, u) = 0;
}
}
}
// 展示去畸变前后的图像
cv::imshow("distorted", image);
cv::imshow("undistorted", image_undistort);
cv::waitKey();
return 0;
}cmake
project(imageBasics)
add_executable(undistortImage undistortImage.cpp)
# 链接OpenCV库
target_link_libraries(undistortImage ${OpenCV_LIBS})
2、stereo双目点云成像
#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <boost/format.hpp> // 字符串的格式化
#include <pangolin/pangolin.h>
#include <sophus/se3.hpp>
using namespace std;
typedef vector<Sophus::SE3d, Eigen::aligned_allocator<Sophus::SE3d>> TrajectoryType;
typedef Eigen::Matrix<double, 6, 1> Vector6d;
// 在pangolin中画图,不是代码的重点
void showPointCloud(
const vector<Vector6d, Eigen::aligned_allocator<Vector6d>> &pointcloud);
int main(int argc, char **argv) {
vector<cv::Mat> colorImgs, depthImgs; // 彩色图和深度图
TrajectoryType poses; // 相机位姿
// 判断是不是在有pose.txt的路径下运行
ifstream fin("./pose.txt");
if (!fin) {
cerr << "请在有pose.txt的目录下运行此程序" << endl;
return 1;
}
for (int i = 0; i < 5; i++) {
boost::format fmt("./%s/%d.%s"); //图像文件格式
colorImgs.push_back(cv::imread((fmt % "color" % (i + 1) % "png").str()));
depthImgs.push_back(cv::imread((fmt % "depth" % (i + 1) % "pgm").str(), -1)); // 使用-1读取原始图像
double data[7] = {0};
for (auto &d:data)
fin >> d;
Sophus::SE3d pose(Eigen::Quaterniond(data[6], data[3], data[4], data[5]),
Eigen::Vector3d(data[0], data[1], data[2]));
poses.push_back(pose);
}
// 计算点云并拼接
// 相机内参
double cx = 325.5;
double cy = 253.5;
double fx = 518.0;
double fy = 519.0;
double depthScale = 1000.0;
vector<Vector6d, Eigen::aligned_allocator<Vector6d>> pointcloud;
pointcloud.reserve(1000000);
for (int i = 0; i < 5; i++) {
cout << "转换图像中: " << i + 1 << endl;
cv::Mat color = colorImgs[i];
cv::Mat depth = depthImgs[i];
Sophus::SE3d T = poses[i];
for (int v = 0; v < color.rows; v++)
for (int u = 0; u < color.cols; u++) {
unsigned int d = depth.ptr<unsigned short>(v)[u]; // 深度值
if (d == 0) continue; // 为0表示没有测量到
Eigen::Vector3d point;
point[2] = double(d) / depthScale;
point[0] = (u - cx) * point[2] / fx;
point[1] = (v - cy) * point[2] / fy;
Eigen::Vector3d pointWorld = T * point;
Vector6d p;
p.head<3>() = pointWorld;
p[5] = color.data[v * color.step + u * color.channels()]; // blue
p[4] = color.data[v * color.step + u * color.channels() + 1]; // green
p[3] = color.data[v * color.step + u * color.channels() + 2]; // red
pointcloud.push_back(p);
}
}
cout << "点云共有" << pointcloud.size() << "个点." << endl;
showPointCloud(pointcloud);
return 0;
}
void showPointCloud(const vector<Vector6d, Eigen::aligned_allocator<Vector6d>> &pointcloud) {
if (pointcloud.empty()) {
cerr << "Point cloud is empty!" << endl;
return;
}
pangolin::CreateWindowAndBind("Point Cloud Viewer", 1024, 768);
glEnable(GL_DEPTH_TEST);
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
pangolin::OpenGlRenderState s_cam(
pangolin::ProjectionMatrix(1024, 768, 500, 500, 512, 389, 0.1, 1000),
pangolin::ModelViewLookAt(0, -0.1, -1.8, 0, 0, 0, 0.0, -1.0, 0.0)
);
pangolin::View &d_cam = pangolin::CreateDisplay()
.SetBounds(0.0, 1.0, pangolin::Attach::Pix(175), 1.0, -1024.0f / 768.0f)
.SetHandler(new pangolin::Handler3D(s_cam));
while (pangolin::ShouldQuit() == false) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
d_cam.Activate(s_cam);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glPointSize(2);
glBegin(GL_POINTS);
for (auto &p: pointcloud) {
glColor3d(p[3] / 255.0, p[4] / 255.0, p[5] / 255.0);
glVertex3d(p[0], p[1], p[2]);
}
glEnd();
pangolin::FinishFrame();
usleep(5000); // sleep 5 ms
}
return;
}
cmake
find_package(Pangolin REQUIRED)
add_executable(stereoVision stereoVision.cpp)
target_link_libraries(stereoVision ${OpenCV_LIBS} ${Pangolin_LIBRARIES})

3、双目视觉、点云拼装
#include <opencv2/opencv.hpp>
#include <vector>
#include <string>
#include <Eigen/Core>
#include <pangolin/pangolin.h>
#include <unistd.h>
using namespace std;
using namespace Eigen;
// 文件路径
string left_file = "./left.png";
string right_file = "./right.png";
// 封装好的在pangolin中画图的函数,不是代码算法的重点
void showPointCloud(
const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud);
int main(int argc, char **argv) {
// 内参
double fx = 718.856, fy = 718.856, cx = 607.1928, cy = 185.2157;
// 基线
double b = 0.573;
// 读取图像
cv::Mat left = cv::imread(left_file, 0);
cv::Mat right = cv::imread(right_file, 0);
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(
0, 96, 9, 8 * 9 * 9, 32 * 9 * 9, 1, 63, 10, 100, 32); // 神奇的参数
cv::Mat disparity_sgbm, disparity;
sgbm->compute(left, right, disparity_sgbm);
disparity_sgbm.convertTo(disparity, CV_32F, 1.0 / 16.0f);
// 生成点云
vector<Vector4d, Eigen::aligned_allocator<Vector4d>> pointcloud;
// 如果你的机器慢,可以把后面的v++和u++改成v+=2, u+=2
for (int v = 0; v < left.rows; v++)
for (int u = 0; u < left.cols; u++) {
if (disparity.at<float>(v, u) <= 0.0 || disparity.at<float>(v, u) >= 96.0) continue;
Vector4d point(0, 0, 0, left.at<uchar>(v, u) / 255.0); // 前三维为xyz,第四维为颜色
// 根据双目模型计算 point 的位置
double x = (u - cx) / fx;
double y = (v - cy) / fy;
double depth = fx * b / (disparity.at<float>(v, u));
point[0] = x * depth;
point[1] = y * depth;
point[2] = depth;
pointcloud.push_back(point);
}
cv::imshow("disparity", disparity / 96.0);
cv::waitKey(0);
// 画出点云
showPointCloud(pointcloud);
return 0;
}
void showPointCloud(const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud) {
if (pointcloud.empty()) {
cerr << "Point cloud is empty!" << endl;
return;
}
// 设置窗口
pangolin::CreateWindowAndBind("Point Cloud Viewer", 1024, 768);
// 开启更新深度缓冲区的功能
glEnable(GL_DEPTH_TEST);
// 开启混合模式、混合常用来绘制透明或半透明的物体
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
pangolin::OpenGlRenderState s_cam(
pangolin::ProjectionMatrix(1024, 768, 500, 500, 512, 389, 0.1, 1000),
pangolin::ModelViewLookAt(0, -0.1, -1.8, 0, 0, 0, 0.0, -1.0, 0.0)
);
pangolin::View &d_cam = pangolin::CreateDisplay()
.SetBounds(0.0, 1.0, pangolin::Attach::Pix(175), 1.0, -1024.0f / 768.0f)
.SetHandler(new pangolin::Handler3D(s_cam));
while (pangolin::ShouldQuit() == false) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
d_cam.Activate(s_cam);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glPointSize(2);
glBegin(GL_POINTS);
for (auto &p: pointcloud) {
glColor3f(p[3], p[3], p[3]);
glVertex3d(p[0], p[1], p[2]);
}
glEnd();
pangolin::FinishFrame();
usleep(5000); // sleep 5 ms
}
return;
}这里对函数cv::StereoSGBM::create介绍一下
static Ptr<StereoSGBM> create
(int minDisparity = 0,
int numDisparities = 16,
int blockSize = 3,
int P1 = 0,
int P2 = 0,
int disp12MaxDiff = 0,
int preFilterCap = 0,
int uniquenessRatio = 0,
int speckleWindowSize = 0,
int speckleRange = 0,
int mode = StereoSGBM::MODE_SGBM);semi-global matching(SGM)是一种用于计算双目视觉中视差(disparity)的半全局匹配算法,
在OpenCV中的实现为semi-global block matching(SGBM)
-
minDisparity 最小的可能的视差值
-
numDisparity 是最大视差减去最小视差
-
disp12MaxDiff是左右图视差检查所允许的最大的不同值
-
P1, P2:控制视差变化平滑性的参数。P1、P2的值越大,视差越平滑。P1是相邻像素点视差增/减 1 时的惩罚系数;P2是相邻像素点视差变化值大于1时的惩罚系数。P2必须大于P1。
-
preFilterCap:预处理滤波器的截断值,预处理的输出值仅保留[-preFilterCap, preFilterCap]范围内的值,
-
speckleWindowSize:检查视差连通区域变化度的窗口大小, 值为 0 时取消 speckle 检查,int 型
-
speckleRange:视差变化阈值,当窗口内视差变化大于阈值时,该窗口内的视差清零,int 型
-
uniquenessRatio:视差唯一性百分比, 视差窗口范围内最低代价是次低代价的(1 + uniquenessRatio/100)倍时,最低代价对应的视差值才是该像素点的视差,否则该像素点的视差为 0
cmake
find_package(Sophus REQUIRED)
include_directories(${Sophus_INCLUDE_DIRS})
find_package(Pangolin REQUIRED)
add_executable(joinMap joinMap.cpp)
target_link_libraries(joinMap ${OpenCV_LIBS} ${Pangolin_LIBRARIES})pose.txt的文件内容
-0.228993 0.00645704 0.0287837 -0.0004327 -0.113131 -0.0326832 0.993042
-0.50237 -0.0661803 0.322012 -0.00152174 -0.32441 -0.0783827 0.942662
-0.970912 -0.185889 0.872353 -0.00662576 -0.278681 -0.0736078 0.957536
-1.41952 -0.279885 1.43657 -0.00926933 -0.222761 -0.0567118 0.973178
-1.55819 -0.301094 1.6215 -0.02707 -0.250946 -0.0412848 0.966741



